OpenAI Whisper 설치하기 / 파이썬 오픈소스 음성인식 AI / Audio to Text / Speech to Text
Open AI Whisper
이 문서는 OpenAI의 Audio to Text (Speech to Text) 프로그램인 Whisper를 로컬 컴퓨터에 설치합니다. 윈도우 PC에 Nvidia 그래픽 카드를 사용할 겁니다.
OpenAI API로 사용하는 방법은 아래 링크를 참고하도록 합니다.
파이썬 OpenAI API whisper 사용하기 - 음성 데이터를 텍스트 스크립트로 변환(Speech to Text model)
파이썬 OpenAI API whisper 사용하기 - 음성 데이터를 텍스트 스크립트로 변환(Speech to Text model)
OpenAI에는 Whisper라는 강력한 Audio to Text 프로그램이 있습니다. 어떻게 만든 건지는 알 수 없지만 음성을 텍스트로 추출하는 기술은 구글의 유튜브 자동 자막보다 뛰어나다는 것이 체감이 됩니다.
digiconfactory.tistory.com
우선 파이썬 버전을 맞춰서 설치해야 합니다. 아래 링크에서 시스템에 맞는 3.9* 버전을 설치합니다. 파이썬 최신 버전이 현재 3.11인데 whisper의 호환이 안되서 다운그레이드 해야 될겁니다. 콘다를 설치하던 가상환경을 만들던 3.99만 맞추면 됩니다. 기존 파이썬 버전과 이름이 충돌하지 않도록 시스템 환경변수를 잘 설정합니다.
Python Release Python 3.9.9 | Python.org
Python Release Python 3.9.9
The official home of the Python Programming Language
www.python.org
PyTorch 설치
다음은 PyTorch를 설치할 차례입니다. 아래 Start Locally에 들어갑니다.
PyTorch
An open source machine learning framework that accelerates the path from research prototyping to production deployment.
pytorch.org
셋팅을 합니다. 여기서는 Stable, Windows, Python, CUDA 11.7로 셋팅 후 pip3 명령어를 실행해서 설치합니다. (CUDA는 Nvidia 그래픽 카드를 사용하는 경우)
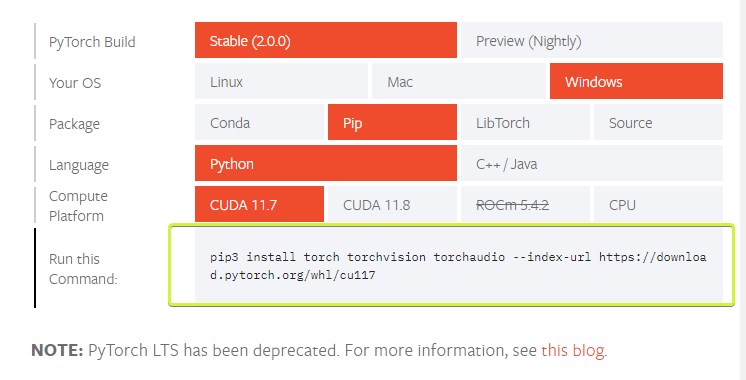
2기가가 넘는 용량이라 조금 시간이 걸립니다. 설치 후에 pip list로 확인해보면 torch, torchaudio 등의 패키지가 설치된 것을 볼 수 있습니다.


FFmpeg
다음은 동영상 처리 라이브러리인 FFmpeg을 설치해야 합니다.
Download FFmpeg
If you find FFmpeg useful, you are welcome to contribute by donating. More downloading options Git Repositories Since FFmpeg is developed with Git, multiple repositories from developers and groups of developers are available. Release Verification All FFmpe
ffmpeg.org
FFmpeg의 설치는 아래 포스트를 참고합니다
FFmpeg 설치와 기본 변환방법 / 동영상 파일 변환 프로그램 (tistory.com)
FFmpeg 설치와 기본 변환방법 / 동영상 파일 변환 프로그램
FFmpeg는 비디오, 오디오 등의 멀티미디어 파일을 처리할 수 있는 프로그램입니다. 이 프로그램으로 할 수 있는게 너무 많아서 공식 웹사이트의 설명에는 '오디오와 비디오를 기록하고(record), 변
digiconfactory.tistory.com
Whisper
그 다음에 Whisper를 설치합니다.
pip3 install setuptools-rust
pip3 install git+https://github.com/openai/whisper.git
Whisper 가 설치되어 있는지 확인합니다.
깃허브의 Whisper 페이지 입니다,
GitHub - openai/whisper: Robust Speech Recognition via Large-Scale Weak Supervision
GitHub - openai/whisper: Robust Speech Recognition via Large-Scale Weak Supervision
Robust Speech Recognition via Large-Scale Weak Supervision - GitHub - openai/whisper: Robust Speech Recognition via Large-Scale Weak Supervision
github.com
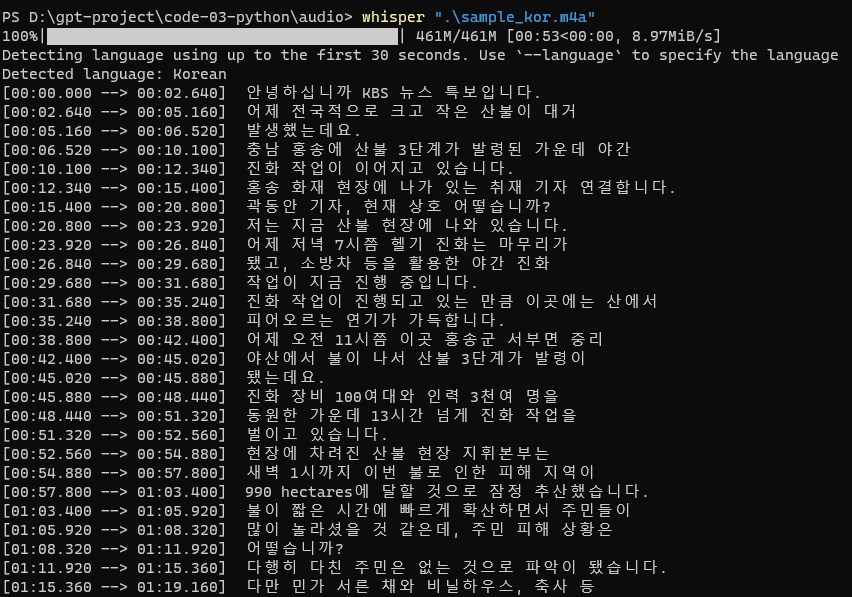
그럼 whisper를 가동해봅니다. 처음 실행하면 뭘 좀 다운로드 받는 시간이 걸립니다. 이것은 어제 OpenAI Whisper API에서 사용한 것과 같은 샘플 파일인데요. 자동으로 언어를 감지하고 텍스트를 생성합니다.
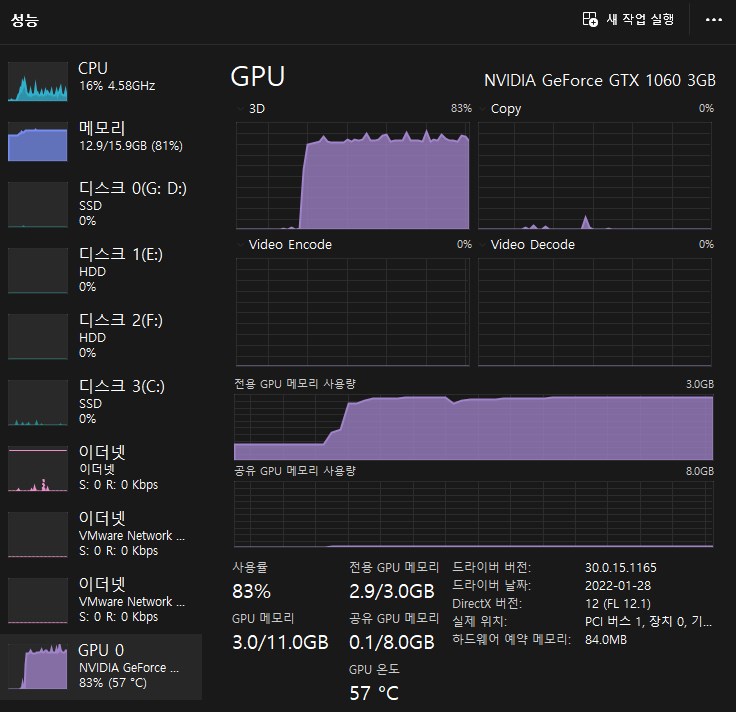
PC 작업관리자의 성능탭을 보면 GPU의 가동이 급격히 늘어납니다. 이것은 1분 짜리라서 가동률이 높지는 않습니다.
워렌버핏의 명연설은 글자수가 1만자가 넘고 16분 정도 분량입니다. (유튜브 영상에서 추출)

Whisper의 작업이 끝나면 디렉토리에 srt, tsv, txt 등 스크립트가 생성되고 json 파일에는 프로그램에 활용가능한 메타데이터가 들어있습니다.

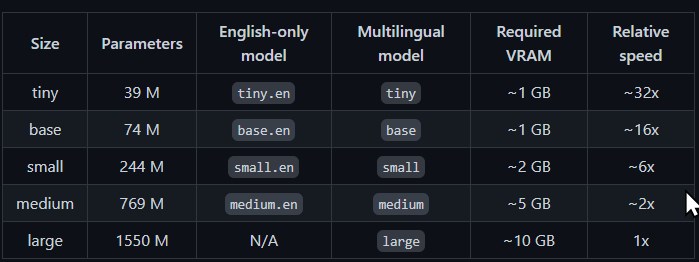
기본 모델로 small 이 선택되어 있는데 정교한 인식을 위해서는 medium 이상 모델을 사용할 수 있습니다. GPU와 그래픽스 카드 성능이 좀 뒷받침되야 할 겁니다. 필자는 GTX 1060 3GB인데 small 정도에서 적당히 쓸만한 성능을 보여줍니다.
(모델 정보는 openai/whisper의 깃허브를 참고)
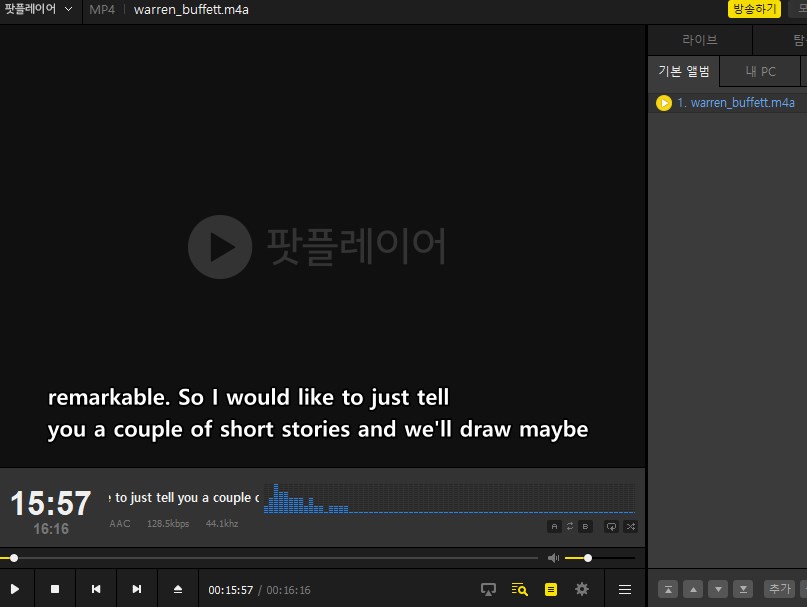
이 상태로 그냥 오디오를 재생해도 SRT 자막이 적용되서 나옵니다. 예전에는 이런 자막을 하나씩 다 치던 시절이 있었는데 이젠 자막 제작의 번거로움도 안녕이네요. (완전히 안녕은 아니고 거의 안녕이다 - 한글 에러율(Word Error Rate)은 14% 정도이다.) 영어는 단어 에러율이 4.2% 밖에 안되기 때문에 사실상 거의 정확합니다. (95%는 제대로 인식한다는 뜻)
tiny model은 파라매터를 더 적게 쓰고 정확도가 조금 떨어지는 대신 속도가 더 빠릅니다. tiny라고 해서 그렇게 떨어지지 않더군요. 특히 영어쪽에는 tiny.en 이라는 더 정확한 모델이 별도로 있습니다.
whisper "음성파일" --model tiny영어는 특히 정확도가 높기 때문에 발음이 정확한 Speech나 News media 등은 그냥 tiny로 놓고 써도 될 것 같습니다. 처리하는 데이터나 오디오다 보니까 Stable Diffusion 같은 그래픽 프로그램 보다는 훨씬 리소스를 덜 잡아 먹기 때문에 필자의 오래된 그래픽 카드로도 충분히 작업이 가증합니다.
요새 AI 프로그램을 돌리다 보니 또 그래픽카드 업그레이드에 대한 욕구가 생기네요. 클라우드에서 돌리면 조금씩 계속 돈이 나가고 내 컴퓨터에서 돌리면 돈을 안나가지만 비싼 그래픽카드가 필요하고, 어딘가 중간 부분에서 절충할 필요가 있겠습니다.
CUDA Driver
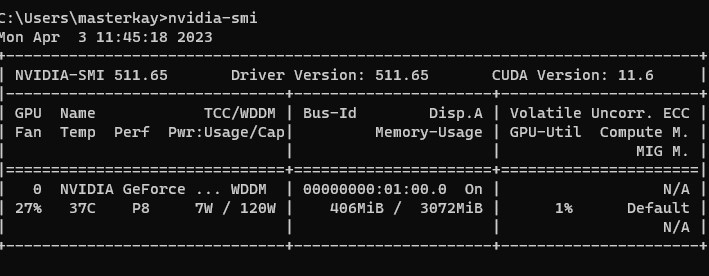
쿠다 드라이버가 없다면 설치하도록 합니다. 필자는 11.6이 설치되어 있는데 Pytorch의 Cuda 11.7버전으로도 동작은 했습니다. 윈도우 같은 경우 nvidia-smi 명령어로 CUDA드라이버 버전을 체크할 수 있습니다.
CUDA Toolkit 11.7 Downloads | NVIDIA Developer
CUDA Toolkit 11.7 Downloads
Resources CUDA Documentation/Release NotesMacOS Tools Training Sample Code Forums Archive of Previous CUDA Releases FAQ Open Source PackagesSubmit a BugTarball and Zip Archive Deliverables
developer.nvidia.com
Python Code
Whisper 가 잘 설치되었으면 파이썬에서 사용하는 것은 어렵지 않습니다. 로컬에서 돌리니까 API 키 같은 것은 당연히 필요없겠네요. 모델만 선택해서(tiny~large) 오디오 파일을 입력하면 됩니다
import whisper
model = whisper.load_model('base')
result = model.transcribe('sample_news.m4a')
print(result['text'])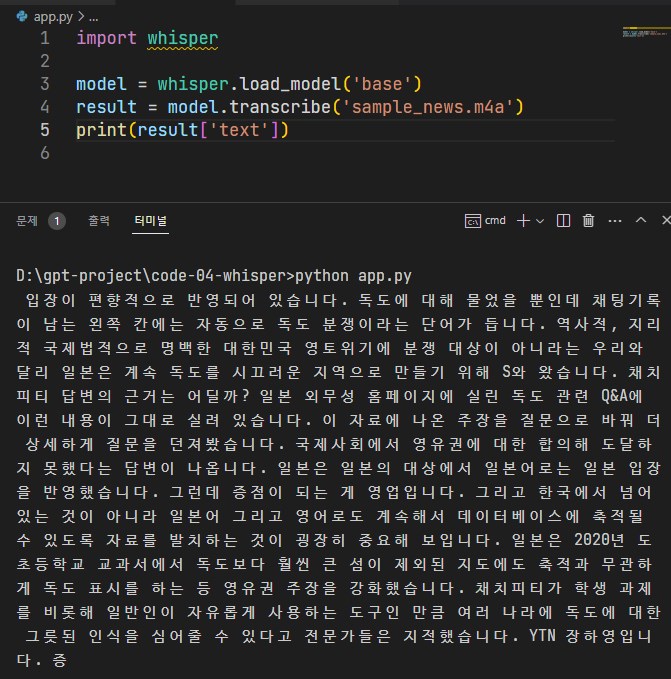
코드를 사용하면 더 많은 일을 시킬 수 있습니다. Real Time Speech To Text, Real Time Translation 등 잘 찾아보면 깃허브에 소스코드가 있습니다. 벌써 Whisper 로 상용 프로그램을 제작하는 개발사도 있구요. 그런 필요한 기능들을 돈을 주고 사는 것 보다 직접 만들 수 있으면 좋겠네요. 예전에는 상상도 하지 못했는데 Whisper 가 오픈소스로 풀려서 이걸로 많은 일을 할 수 있게 되었습니다.