C언어 2 - 2 | 자료형 | 아스키코드
C언어에 대한 내용을 다룰 때 아스키 코드에 대한 이야기를 하려고 생각하고 있었다.
다행히 요즘은 인터넷에 아스키 코드에 관해서는 쉬운 설명도 많이 있고 한글 자료도 많다.
아스키코드는 사람과 기계간 커뮤니케이션을 위한 일종의 암호와 같다.
우리는 컴퓨터를 사용할 때도 사람의 언어를 쓴다. 그걸 당연하게 생각한다. 그러나 컴퓨터는 다르다. 지난 포스트의 내용처럼 모든 것을 0과1로 처리한다.
컴퓨터가 처음 개발된 곳을 생각해보자. 미국에서 개발되었다. 미국의 언어는 영어다. 지금이야 모두가 컴퓨터에서 자유롭게 영어를 사용한다. OS는 영어 사용자들이 영어로 된 C언어와 어셈블리어를 가지고 개발되었고, 문서도 기본 영어로 쓰여진다.
그러나 처음부터 컴퓨터에 영어를 사용하지는 못했다. 영어는 컴퓨터의 기본 언어가 아니기 때문이다. 사람들은 컴퓨터를 사용하기 위해 0과1로 만들어진 기계어를 직접 입력해야 했다.

hello world 가 아니라 어떤 코드를 만들어도 인간이 이해할 수 없는 코드가 만들어 질 것이다.
그러다보니 미국 사람들은 당장 컴퓨터에서 영어를 쓰고 싶어졌다. 문자열을 입력하기 위해서 입력장치에서 HELLO 라고 입력하길 원해지 0000 0100 ... 같은 코드를 입력하길 원하는 사람은 아무도 없다.
그래서 사람들은 규칙을 만들기로 했다. 사람이 키보드로 입력했을 때 기계가 알아들을 수 있도록 변환하는 규칙이다. 또한 기계가 사람에게 메세지를 내보낼때 0001 1000 ... 같은 숫자의 연속이 아니라 "Mission Complete" 같이 인간이 알아들을 수 있는 말을 하도록 하는 규칙이다. 이것이 아스키 코드이다. (ASCII, 1967년에 표준으로 제정)
다행인지 불행인지(다른 언어를 사용하는 민족에게) 컴퓨터를 개발하던 사람들은 영어를 사용하고 있었고 영문 알파벳의 숫자는 적었다. 소문자 대문자를 다 표현하기 위해서 52개의 저장공간이면 충분하다.
초기의 아스키코드는 7비트였다. 메모리 단위가 1바이트이므로 1비트가 남는데 나머지 1비트는 통신에러를 검출하기 위한 수단으로 사용되었다.
https://namu.wiki/w/%EC%95%84%EC%8A%A4%ED%82%A4%20%EC%BD%94%EB%93%9C
아스키 코드 - 나무위키
UTF-8의 경우 ASCII 영역은 그대로 1바이트를 사용하기 때문에 호환이 된다. 반대로 말하자면 UTF-8 문서라도 ASCII 영역에 해당하는 문자만 적혀 있고 BOM까지 없다면 그냥 ASCII 문서와 다를 게 없다. ��
namu.wiki
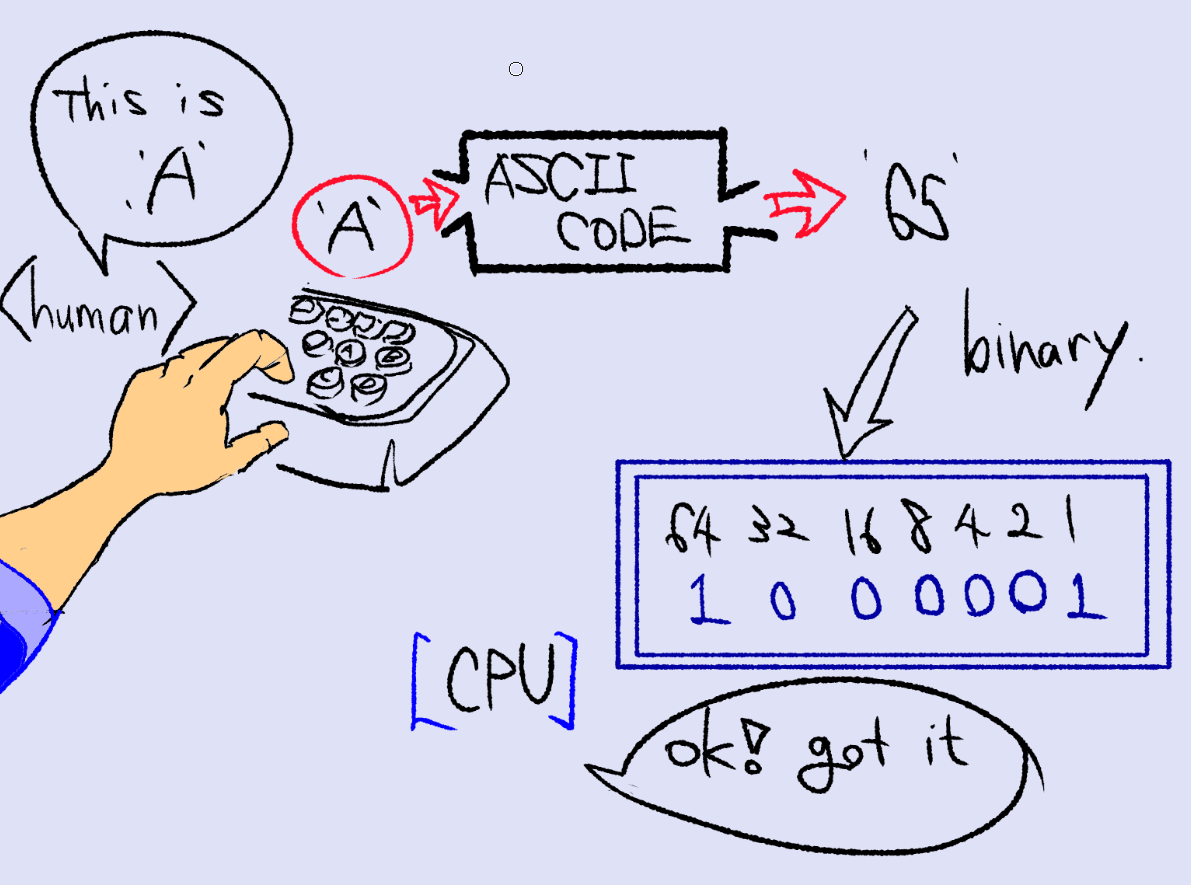
아스키코드를 사용함으로써 이제 기계어를 사용하지 않아도 컴퓨터에 입력이 가능해졌다.
사용자가 대문자 A를 입력하면 100 0001 의 신호가 컴퓨터에 전달이 되고 CPU는 아스키 코드에 해당하는 폰트를 가져와서 화면에 출력한다. 대문자 A의 폰트는 아래와 같이 여러개의 픽셀정보를 저장한다 (예시임, 폰트에 따라 다르다) 사용자는 키보드와 7비트 숫자만으로 텍스트를 출력할 수 있다. 폰트는 바뀌어도 상관이 없다.


Ascii Table - ASCII character codes and html, octal, hex and decimal chart conversion
ASCII Table and Description ASCII stands for American Standard Code for Information Interchange. Computers can only understand numbers, so an ASCII code is the numerical representation of a character such as 'a' or '@' or an action of some sort. ASCII was
www.asciitable.com
아스키코드의 테이블은 위의 웹사이트에서 확인할 수 있다. 확장 아스키코드도 있다.
아스키 테이블에는 영문자 뿐만 아니라 프로그램을 제어하기 위한 문자나, + - 같은 수학기호 등이 저장되어 있다. 확장 아스키값에는 유럽의 문자들도 다소 포함되어 있다. 즉 8비트를 사용하여 0부터 255까지 256개의 숫자를 문자에 대응시켜서 문자를 포함한다.
C언어에서 문자를 담당하는 자료형은 char이다. printf 포맷으로 %c에 아스키 코드에 해당하는 숫자를 대입하면 콘솔에 문자를 출력한다. %d 포맷은 decimal(10진수) 이다.
#include <stdio.h>
#include <windows.h>
int main(void){
SetConsoleOutputCP(1252);
int i;
for (i = 0; i < 256; i++){
printf("%3.3d : %3c || ",i,i);
if (i%10==0) printf("\n");
}
} 
확장 아스키코드에는 여러가지 버전이 있으며 출력된 코드는 ANSI 라틴어1이다.
아스키 코드의 7비트까지 (0~127까지) 유니코드와 하위호환이 된다. 한글 프로그램은 UTF-8으로 많이 쓰는데 0~127까지는 호환이 되니까 동일한 방법으로 영문자를 사용할 수 있다.
*참고영상 아스키코드의 계산법
https://www.youtube.com/watch?v=H4l42nbYmrU