C언어 | 이진트리와 자료구조에 대한 잡설
*이 포스팅에서는 이진 트리를 만들어볼 예정이었으나 잡설이 길어져서 포스팅을 분리한다.
*이진검색트리 (Binary Search Tree)의 조건
- 이진 트리는 루트를 중심으로 노드가 왼쪽에 하나 오른쪽에 하나씩 연결된다.
- 노드 N(어느 한 노드)을 기준으로 왼쪽 트리의 키값은 노드 N보다 작아야 하고, 오른쪽 트리의 키 값은 노드 N보다 커야 한다.
- 같은 키값을 갖는 노드는 없다.
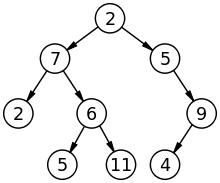
이진 검색이라는 것도 있는데 이진 트리와 이진 검색은 차이가 있다. 이진 트리가 아니더라도 정렬을 하면 이진 검색이 가능하다. 반면 이진 트리는 값의 추가시 함께 자동으로 정렬된다.
이진 트리는 좀 복잡하다.
하위 노드에 접근하기 위해서 링크 연결과 재귀함수(resursive function)을 사용하는데 포인터 연산으로만 연결시켜야 하는 어려움이 있다. 게다가 이중 포인터를 사용하는 경우도 있어서 코드를 읽기가 더 어려워진다.
알고리즘에 입문하여 한번만에 완전한 이진트리를 완성할 수 있다면 보통 사람보다 높은 재능의 소유자라고 말할 수 있다. C언어 초창기에는 자료구조를 스스로 만들어서 사용해야 했다. 제한된 메모리와 CPU환경에서 성능이 뛰어난 알고리즘이 중요했고 알고리즘의 원리를 이해하고 상황에 따라 수정과 추가 할 수 있어야 했다. 컴퓨터 서비스 안정성을 위해서 자료 구조를 다루는 것이 매우 중요한 일이었다.
현재는 어떤가? C++ 의 STL 컨테이너와 자바의 컬렉션스 프레임워크에서 십년 이상 개발되고 사용된 안정성 높은 자료형을 제공한다. 클래스의 형식으로 제공하기에 안정성은 더 높아졌다. 코드의 길이가 길어지면서 속도는 조금 떨어졌을지 모르지만 그것을 상회하고도 남는 컴퓨터 하드웨어의 발전으로 컴퓨팅 환경은 나날이 나아지고 있다.
최근에 각광을 받기 시작한 딥러닝, 빅데이터 분석, 컴퓨터 비전 등은 하드웨어와 소프트웨어의 동시적 발달이 촉진한 부분이 크다. 방대한 데이터를 처리할 하드웨어가 필요했고 거기에 맞춰 소프트웨어를 구현한 것이다.
현재 대세를 이루는 유튜브는 서버 스테이션과 개인 PC의 성능발달도 한몫했다. 불과 몇년전까지도 동영상을 인코딩 하는 시간이 만만치 않았다. 10분짜리 고화질 영상을 인코딩하기 위해 몇 시간 걸리기도 했다. 지금은 보통의 영상은 FHD도 10분 정도면 충분하다. 유튜브에 업로된 비디오 파일은 유튜브가 다시 검색하여 저작권 분석 부터 카테고리 분류와 21억 사용자 중에 어디사는 몇명에게 추천 영상으로 보내야할 것 까지 결정한다.
보면서도 놀라운 일이고 말로 설명해도 실로 놀라운 일이다. 매일 일상에서 이루어지고 있다니 상상의 역사에 살고 있는 것 같다.
다시 이진 트리로 돌아와서 이런 자료형을 개발하는 사람들은 컴퓨터과학 연구소나 시스템 소프트웨어를 만드는 MS 같은 회사에서도 특별히 설계를 하는 프로그래머들이거나 오라클 같은 데이터베이스 회사의 직원일 것이다. 시스템 구조는 여러 사람이 만들 필요가 없다. 컴퓨터 회사의 대부분의 직원은 고객 서비스에 더 중점을 둔다. 아마존에는 100만명의 직원이 있지만 그 들중 자료구조를 개발하는 사람은 손에 꼽을 정도 일 것이다. 거꾸로 말하면 100만명이 자료 구조를 만드는 것도 정상이 아니다.
자료 구조는 특별한 몇 사람들을 위한 기술일 수도 있다. 시스템의 설계자, 아키텍쳐, 디자이너라고 불리는 그들이다. 그런데 왜 이런 것을 가르치는 거고 배워야 하는 것일까? 의문을 품지 않을 수 없다.
첫번째는 내가 설계하지 않지만 자료 구조를 더 잘 이해하고 사용할 수 있도록이다.
예를 들어서 자바에서는 콜렉션 프레임 워크를 제공한다. 클래스로 제공되고 일반적으로 필요한 대부분의 기능이 메소드로 구현되어 있다. 자바 개발자들이 오랜 시간동안 업그레이트 해왔기에 성능도 좋고 가이드에 따라 사용하면 안정성이 높다. 자료 구조를 배우면 이런 자료형들의 특성에 대해 더 잘 이해할 수 있고 어떤 상황에 어떤 자료형을 사용해야 할 지 판단할 수 있다.
두번째는 알고리즘 실력을 향상시키기 위해서이다. 꼭 자료구조가 아니라 애플리케이션을 만들더라도 알고리즘이 필요하다. 결국 애플리케이션은 어떤 자료구조를 가지고 동작을 정의하는 과정이다. 문제를 해결한다고도 하고 이를 알고리즘이라고 한다. 결과보다 과정이 중요한게 알고리즘이라 직관적이기 보다는 논리적이고 절차적이다.
자료구조를 잘 안다면 애플리케이션의 로직을 더 효율적으로 작성하는데 도움이 된다. Optimization(최적화)는 언제나 사람들이 원하는 결과물이다. 최근의 소비자는 심지어 무료로 공개한 게임을 하나 다운로드 받아 구동하는데에도 최적화를 따진다. 그 소프트웨어를 내 PC의 자원과 나의 시간과 노력을 소비하여 기꺼이 실행시키고 있는 것이다. 만드는 사람은 소비자가 어떤 불평을 해도 들어야 한다. 당연히 잘 만든 소프트웨어라면 소비자가 만족할 것이다.
컴퓨터의 역사는 이제 좀 되었다. 컴퓨터를 사용하는 사람들의 취향은 많이 높아져 있다. 알고리즘도 그래야 한다.
이제 사람들은 구글의 알고리즘... 처럼 상당히 높은 알고리즘을 기대해서 웬만큼 사람들을 만족시켜주기 어렵다.
구글이 잘하는 것을 보통 사람이 따라 하기 힘들다. (그랬다면 이미 구글에 입사했을 것이다)
문제는 대부분의 앱에서 판단하는 기준점을 찾기가 쉽지 않다는 것이고 코드의 유지보수에는 비용과 자원이 들어가니 어느 정도 타협점을 찾는 것이다. 예전에는 느리게 돌아가건 소프트웨어가 하드웨어 사정이 나아진 지금은 별로 부담스럽지 않은 경우도 흔히 볼 수 있다.
빨라지면 뭐든지 좋긴 한데 그것도 1시간 작업을 10분으로 단축시켜 줄때 좋은 거지 10분작업을 5분으로 줄여줄때의 기분은 예전보다 못하다. 이걸 경제학에서는 한계효용의 체감 법칙이라는 어려운 말로 설명한다. 쉽게 말해 배고플때 소고기를 먹을 때 느낌과, 이미 배부르면 한우 맛도 별로 인 것과 같은 이야기다. 뭐든지 한번에 받아들이는 양에는 한계가 있다.
그러니까 자료 구조는 좀 더 성능상의 문제가 민감한 분야에서 의미를 가지게 된다. 예를 들어 임베디드 소프트웨어라든지 IOT (사물인터넷) 은 하드웨어 제약이 있으니 좋은 알고리즘이 필요하다. 파이썬이 많이 쓰이니까 C코드를 같이 사용할 수도 있다. 어쨋든 자료구조와 알고리즘의 공부는 의미를 가진다.
이런 논의는 끝이 없을 것 같다. 개인취향으로는 좀더 컴퓨터의 원시적인 설계 구조를 들여다보고 조작할 수 있는 즐거움이 있다고 본다. 컴퓨터의 원리를 알기 위해 끓임없이 그 속으로 들어가 보는 것도 의미가 있다. 대부분의 사람들 심지어 컴퓨터 학자들 조차도 그 원리에 대해 완전하게 이해하기 어렵다고 한다. 하지만 사용하는 것은 누구나 할 수 있다. 이런 질문들은 꽤 매력적이다. 답변이 별로 나올 것 같지 않은 질문이기 때문이다.