파이썬 코딩 1-6 | 파이썬의 자료형 | 딕셔너리
*딕셔너리
기존 언어를 접해본 사람들이 보면 파이썬의 자료형들은 좀 특이하다. 리스트,튜플 다음에 딕셔너리 자료형에 적응하는 것도 새로운데 딕셔너리라는 것 까지 나왔다. 딕셔너리,,, 흠 dictionary는 중학영어에서 배웠을 것이다. '사전' 이라는 뜻이다.
사전처럼 찾는 방식이라는 점에 주목할 필요가 있다. 사전을 찾을 때의 방식으로 자료가 저장되고 검색이 된다는 것이다.
예를 들어 이렇게 저장할 수 있다.
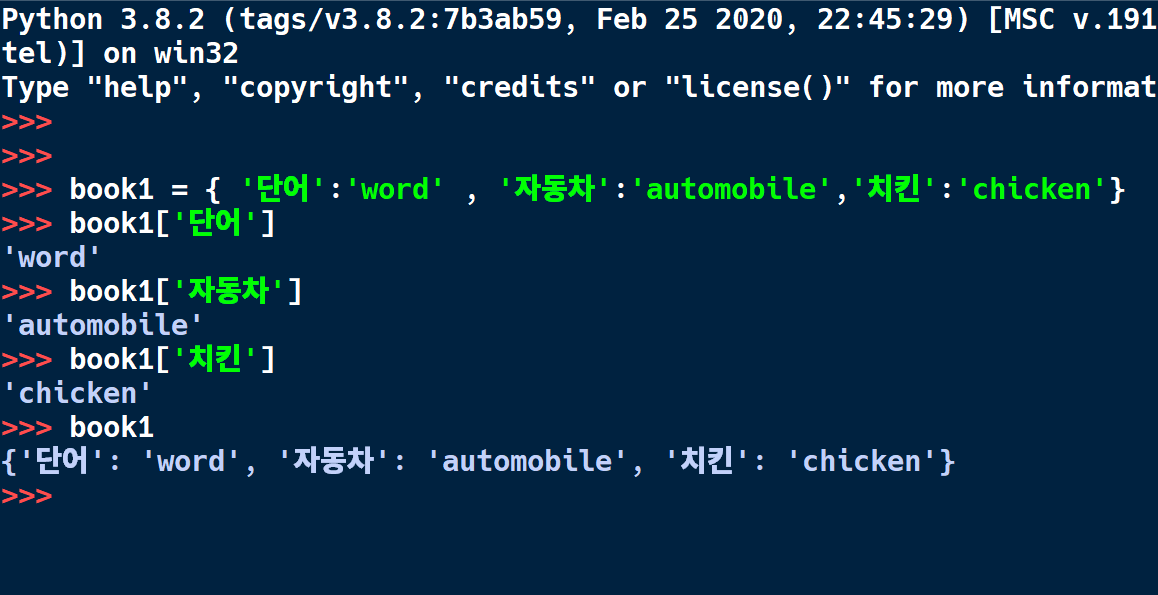
각 단어에 대응되는 말 그대로 사전이다. 숫자형도 사용할 수 있다. 예를 들어 사람들의 키를 저장한다고 치면...

사람 이름에 대응하여 키가 나온다. (키는 실수형이다) 그동안 사용했던 리스트나 튜플은 A[0],A[1],A[2]... 처럼 배열의 인덱스를 순차적으로 사용해야 했는데 딕셔너리 자료형은 순서가 없다. 대신 Key 라고 하는 유니크한 값이 배열의 인덱스를 대신한다.
다음과 같이 매우 유연하게 딕셔너리에 저장할 수 있다. 마치 데이타베이스 테이블을 보는 것 같다.
book1 = {1: 'a', 2:'b', 3:'c', 4:'d'}
book2 = {1: 100, 2: 200, 3: 300}
book3 = {1: 'Hello', 2:'How are you?', 3:'I''m fine',4:'Thank you'}
book4 = {'홀수': [1,3,5,7,9], '짝수': [2,4,6,8,10]}
book5 = {'id': 1001, 'name': 'MJ', 'number':23}
앞쪽이 KEY 즉 열쇠이고 뒤쪽이 값 (Value) 이다. 내가 찾으려는 값이 있다면 열쇠를 꽂으면 된다. 이런 대응관계를 해시(Hash)라고 한다. 일반인들도 많이 쓰는 Hash 태그라는 말도 내가 찾는 주제가 열쇠가 되는 것이고 찾아서 나오는 값(이미지)이다. 관련된 열쇠를 가지고 있어야 문을 열수가 있다. 다만 프로그램에서는 대응관계가 일대일이다.
딕셔너리의 Key와 Value는 한쌍을 이룬다. 검색엔진처럼 여러개를 찾아주진 않는다.
*딕셔너리 조작하기(추가,삭제,변경)
book1 = {1: 'Hello', 2:'My name', 3:'is Mike'}
book1[4] = 'How are'
book1[5] = 'you today'
마치 배열의 인덱스 처럼 보이지만 그렇지 않다. book1 에서 3개의 키와 값들을 저장하고, book1[4]와 [5]에 새로운 키와 값을 입력한 것이다.
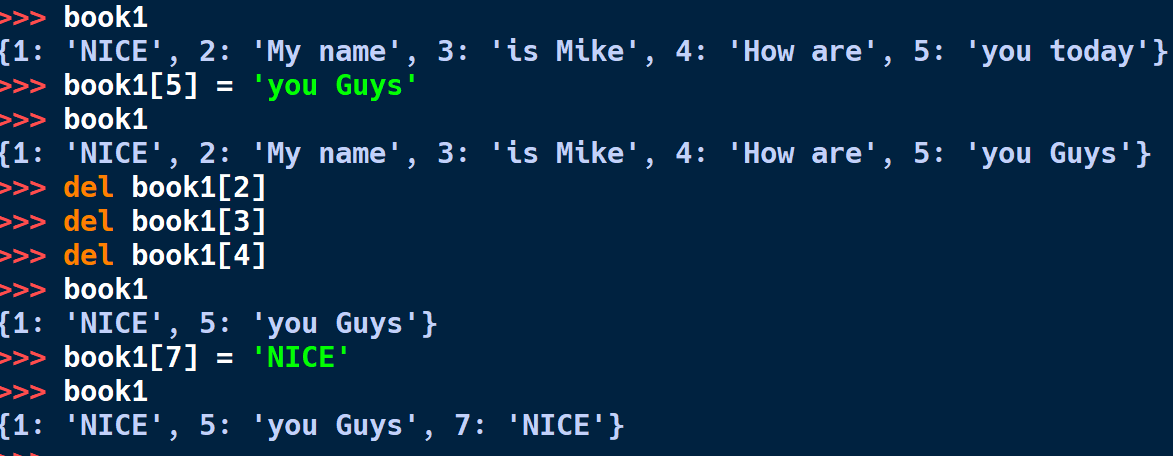
변경하기 위해서는 키값을 이용해야 한다. 그러므로 키값은 유니크하다. 키값이 같은 딕셔너리는 없다. 리스트에서 인덱스가 중복되지 않는 것과 같은 원리다. 키에 대입한 값은 변경된다. 삭제도 키값으로 한다.
한편 키에 대응되는 값이 같은 것은 괜찮다. book1의 키값 1과 7은 둘다 값이 'NICE'다. 이것은 괜찮다. 1:'NICE' , 1:'GOOD' 과 같이 키가 두개가 될수는 없다. (그냥 안된다)
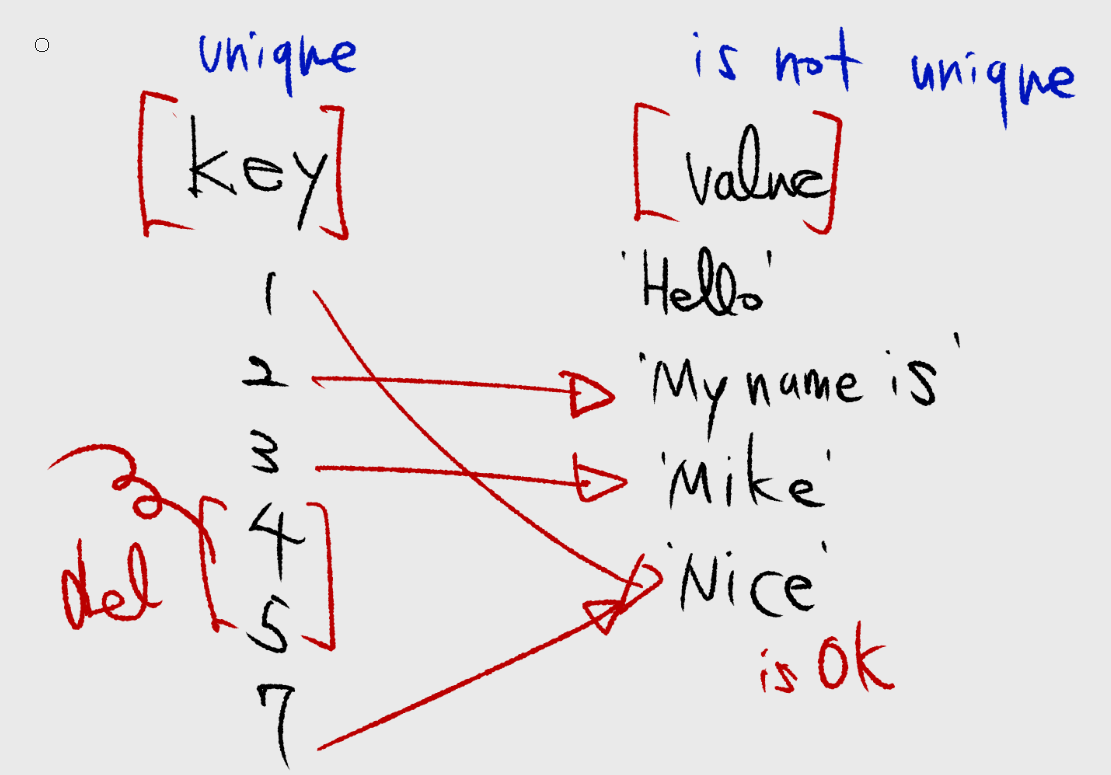
딕셔너리는 인간적인 자료형이다. 컴퓨터야 0부터 순차적으로 세는 것이 더 좋을 것이다. (컴퓨터에게 더 좋은건 이진 계산만 하는 것이다) 인간은 사물을 그렇게 기억하지 않는다.

우리는 손흥민하면 축구를 떠올리고 정찬성하면 UFC를 떠올린다. 손흥민의 직업을 찾기 위해서
SoccerPlayer[0],
SoccerPlayer[1],
...
이렇게 찾지 않는다.
우리 머리속에서 '손흥민'은 '축구'에 그대로 연결되는 것이다. 또한 손흥민도 '축구' 이고 차범근도 '축구' 이다. 그런데 그 반대인 '축구'는 키가 될 수 없다. '축구'는 한 사람만을 위한 것은 아니기 때문이다. 뭐 굳이 프로그램안에 넣으라면
{'축구선수' : {'손흥민','차범근','박지성', 등등}
이렇게 넣을 수는 있겠지만 선수가 한명 추가되면 전체 명단을 다시 써야한다. 그럴 바에 이름과 축구를 하나 추가하는게 낫다.
이런 자료의 저장방식의 단점도 볼 수 있다. 리스트와 튜플에서는 순차적으로 접근가능하다는 이점 때문에 인덱싱과 슬라이싱 기법을 통해서 다양한 방법으로 데이터에 접근할 수 있었지만 딕셔너리는 단 한가지 방법 밖에 없다. Key를 넣어서 Value를 꺼내는 방식이다.
김연아의 종목을 알고 싶으면 book1에 '김연아'라는 Key를 넣으면 된다. '김연아'라는 Key값에 1을 더한다고 다음 값이 출력되지 않는다. (이 블로그의 특징은 당연한 이야기를 글로 적는다)
* 딕셔너리 키의 튜플

딕셔너리의 키값은 유니크하다고 했다. 값은 유일해야 하고 변하지 않아야 한다. 그래서 변형이 가능한 리스트는 키값이 될 수 없다. 튜플은 immutable (불변) 이므로 사용가능하다. Key 값은 딱딱하지만 Value에 있어서는 유연하다. 파이썬에서 사용되는 자료형은 Value에 저장가능하다. 클래스의 참조변수도 Value에 저장가능하다.

*딕셔너리 함수
리스트에서도 있었지만 딕셔너리 자체 함수들을 몇가지 살펴본다. 딕셔너리 같은 자료형을 iterable 이라고 한다. 쉽게 생각하면 for문에 무작정 넣으면 순차적으로 하나씩 내용을 뽑아 온다는 말이다. 리스트나 튜플도 가능하고 딕셔너리도 가능하다. 순차적 인덱스만 사용하지 못할 뿐이지 어쨋든 저장은 코딩된 순서대로 되있다.(논리적으로)
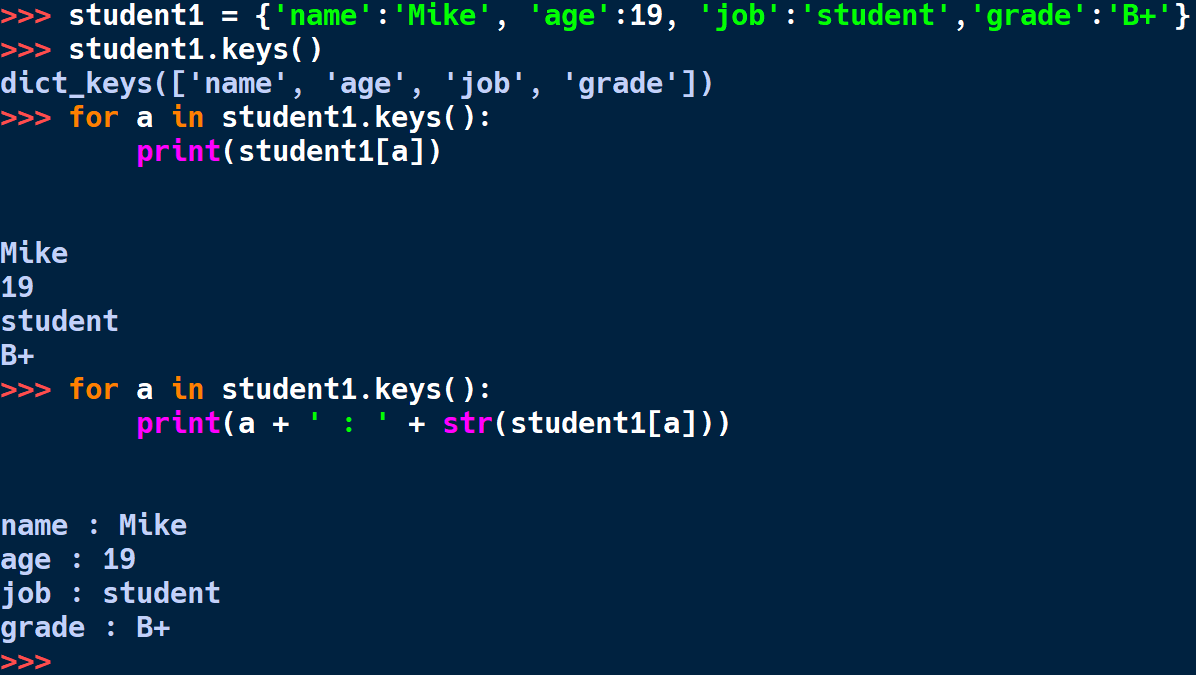
그런 성질을 활용해서 for 문으로 조작할 수가 있다. keys()함수는 키값을 가 dict_keys 클래스 형태로 가져온다. iterable로 사용하면 키값만 추릴 수 있고, 키를 꺼내오면 당연히 열어서 가져오면 된다. for문을 변형하면 다양하게 사용할 수 있다. 만약에 키값을 리스트로 저장하고 싶다면 list(student1.keys()) 을 사용한다. 그러면 리스트의 인덱스도 쓸 수 있다. 이렇게 자료의 형변환이 유연한 것이 파이썬의 특징이다. 되는 것과 안되는 것이 있는지는 직접 실행해 보는것이 가장 기억에 남을 것이다.
인터프리터에서 아래 함수들을 실행해본다. values와 items 메소드의 원리도 같다. items의 경우 튜플을 리스트 형태로 묶을 수 있음을 보자. 튜플이 바로 딕셔너리의 성질이다. 하나의 키와 하나의 값을 묶는 것이다. 키는 유니크 해야한다. 유니크한 키 이거 데이타베이스 시간에 프라이머리 키 그런 것과 유사하다.
get메소드는 student1[키값] 과 한가지 차이가 있다. get메소드에 없는 키값을 넣으면 None (참조없음, 파이썬 키워드)을 돌려준다. student1[없는키값]을 넣으면 오류가 발생한다. 상황에 따라 프로그램 제어를 위해 두 가지 경우를 사용할 수 있다. get메소드는 None 대신에 default 값을 리턴할 수도 있다.
>>> student1.values()
>>> list(student1.values())
>>> student1.items()
>>> list(student1.items())
>>> student1.get('name')
>>> student1.get('age')
>>> student1.get('job')
딕셔너리를 삭제할 때는 clear 메소드다.

Key 값을 확인할 때는 in 을 사용한다. 불린으로 리턴한다.

입문 과정이면 딕셔너리에 대하여는 이정도면 충분할 것 같다. 파이썬도 리스트,튜플,딕셔너리 요런게 약간 고비인데 어려우면 리스트를 많이 연습해본다. 리스트를 잘 사용할 수 있으면 다른 자료형도 어렵지 않다. 비슷한 속성을 공유하기 때문이다.