C언어 자료구조 - 배열의 구조
C의 대표적 자료 구조인 배열에 대하여 알아본다. 배열은 대부분의 언어에 기본으로 장착되어 있는 자료형태이다.
컴퓨터는 모든 데이터를 0과1의 이진 데이터의 형태로 저장한다.
이진법과 C의 자료형에 대하여는 아래 포스트에 내용이 정리되어 있다.
이진법과 2의 보수
이진법은 무엇인가? 아니 그 전에 십진법에 대해서 알아본다. 십진법은 누구나 알고 있는 진법이다. 십진법이라고 가르쳐주지 않아서 헷갈릴 뿐이다. 바로 이것이다. 왼손 새끼손가락부터 오른�
digiconfactory.tistory.com
C언어 2 - 1 | 자료형 | char 형 변수의 사용
C언어의 자료형을 배워본다. 자료형은 무엇일까? 자료형을 논하기 전에 먼저 컴퓨터가 정보를 어떻게 다루는지 알아 봐야한다. 사람은 10진법에 익숙하지만 컴퓨터는 이진법으로 계산한다. 컴퓨
digiconfactory.tistory.com
거대한 컴퓨터 자료구조의 속으로 들어가기 위해서 0과 1부터 추적하는 것은 좋은 시작이다.
int 형(정수형) 변수로 배열을 만들 것이다.
현재 시스템이 최근의 인텔 CPU에 64비트 윈도우 시스템이라면 int형은 32비트일 것이다.
* 아래와 같이 변수를 선언하고 초기화 한다.
int a = 0;* 그러면 프로그램의 실행시에 메모리에 아래와 같이 저장된다.
a : 0000 0000 0000 0000 0000 0000 0000 0000
32bit (4byte x 8)* 다른 값을 할당 한다.
a = 15* CPU는 메모리에 다음처럼 쓰기를 한다.
a : 0000 0000 0000 0000 0000 0000 0000 1111
32bit (4byte x 8)이것이 int 형 변수 하나를 취급할 때의 모습이다.
그 다음은 배열로 만들어 본다.
int a[5] = { 0, };이는 int 형 변수를 5개 만들어서 메모리에 배열하겠다는 말이다. 배열 후에 모두 0으로 초기화를 한다.
a[0] : 0000 0000 0000 0000 0000 0000 0000 0000
a[1] : 0000 0000 0000 0000 0000 0000 0000 0000
a[2] : 0000 0000 0000 0000 0000 0000 0000 0000
a[3] : 0000 0000 0000 0000 0000 0000 0000 0000
a[4] : 0000 0000 0000 0000 0000 0000 0000 0000
(4 byte x 8 bit) x 5 ea = 160 bit위와 같은 형태로 메모리에 배열된다. 말 그대로 정확하게 줄을 세워놓은 것 이다.
(더 미궁에 빠질 수 있으므로 엔디언에 대한 설명은 제외한다)
여기까지 C언어 코드로 나타내면 다음과 같다.
#include <stdio.h>
void main(){
int a[5] = { 0, };
for(int i; i < 5; i++){
printf("value: %d, address : %d \n", a[i], &a[i]);
}
}
C언어의 주소 연산자를 사용해서 십진 값으로 표현하면 메모리 주소가 16,20,24,28 처럼 똑같은 4의 차이다. 이는 저장된 간격이 4바이트로 같다는 뜻이다. 1000개를 할당해도 같은 간격을 볼 수 있다.
(주소는 각 시스템의 하드웨어 상황에 따라 달라진다.
%p가 아니라 %d를 사용 하면 16진수를 몰라도 알 수 있다. 물론 16진수로 변환하면 값은 동일하다)
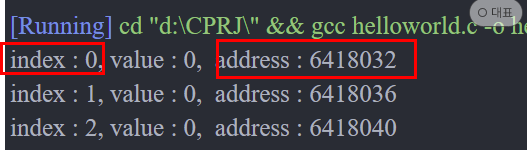

이것이 배열의 특성이다. 인덱스가 있기 때문에 값에 즉시 접근이 가능하다. 995번째 데이터를 가져오고 싶으면,
printf("%d", a[994])인덱스는 0부터 시작하니까 인덱스는 994를 찍으면 된다. 프로그램은 배열의 0번째 주소값에 4바이트 x 994 만큼의 값을 더하여 즉시 메모리의 주소 6422008을 알아낼 수 있다. 따라서 배열의 속도는 다른 탐색구조에 비해서 빠르다.

*. char 형
#include <stdio.h>
void main(){
char a[5] = { 'a', 'b', 'c', 'd', 'e'};
for(int i; i < 5; i++){
printf("index : %d, value : %c, address : %d \n", i, a[i], &a[i]);
}
}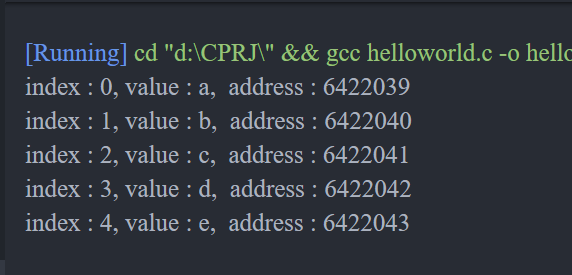
1 바이트인 char형도 같은 구조다. 바이트의 크기가 달라지니 char형 요소 5개의 배열을 만들면 5바이트를 차지한다.
*. sizeof 연산자의 사용
#include <stdio.h>
void main(){
char a[5] = { 'a', 'b', 'c', 'd', 'e'};
for(int i; i < (sizeof(a)/sizeof(a[0])); i++){
printf("index : %d, value : %c, address : %d \n", i, a[i], &a[i]);
}
printf("배열의 요소 개수 : %d, 배열하나의 사이즈: %d\n", sizeof(a),sizeof(a[0]) );
}
sizeof 연산자를 사용하면 배열 계산이 쉽다. 배열의 전체 바이트 크기는 sizeof(a) 로 배열요소의 바이트값을 구하려면 sizeof(a[0]) 값을 구한다.
예를 들어 int 형 변수 b에 배열 30개를 할당했다. 4바이트 일 수도 있지만 시스템에 따라 차이가 날 수도 있다. (int 는 구세대 시스템에서 16비트인 경우가 있다) 그런 경우 sizeof 연산자로 정확하게 계산할 수 있다. 2바이트면 x 30 에 60 바이트. 4바이트면 x 30 에 120 바이트.
배열의 방식으로 프로그래머는 데이터를 시스템에 로드하기 전에 메모리를 얼마 정도 사용하게 되는지 예상할 수가 있다. 보통 실행코드는 용량이 대체적으로 정해져 있고 적은 편이다. 반면 데이터의 양은 얼마든지 추가될 수 있다.
MS의 엑셀자료를 좀 다뤄봤다면 엑셀의 데이터만으로도 몇메가는 우습게 넘어가는 경험을 해봤을 것이다. 어떤 자료를 사용하건 데이터의 용량을 줄이면서 효율적으로 처리하는 것이 시스템 설계자들의 목표이다. 잘 생긴 선수를 육성하려면 더 강하고 빠르고 정확하게 플레이하는 법을 가르쳐야 한다. 그것이 기계를 육성하는 프로그래머의 올바른 자세다.
이 포스트는 C언어 문법에 대한 설명을 대체로 생략하고 자료구조의 설명에 대한 부분에 집중했다.
C언어의 문법은 별도 카테고리에서 정리하고 있으니 배열의 문법을 정리하면 여기에 링크를 걸도록 하겠다.

참고: C 메모리 구조에 대한 설명이 잘되어 있다. C언어의 기본 array는 지역변수 처럼 스택에 저장되는데 malloc 함수로 별도로 heap에 할당할 수 있다. 특히 C#의 경우 기본 array 도 fixed size 고정 크기로 엄격하게 관리하는데 메모리의 영역은 heap에서 관리한다. heap이건 stack 이건 한번 생성된 배열은 고정 크기를 갖기 때문에 속도면에서 유리하다고 할 수 있다. C#이 문법적으로 쉽게 가려고 많이 변했지만 성능에 대한 부분은 C의 계승자 답게 신경을 쓴 부분이다.
7. Memory : Stack vs Heap
When should you use the heap, and when should you use the stack? If you need to allocate a large block of memory (e.g. a large array, or a big struct), and you need to keep that variable around a long time (like a global), then you should allocate it on th
gribblelab.org