C언어 3 - 1 | 상수 숫자형 리터럴, 문자형 리터럴 const 키워드
수를 다루는 저장 공간을 구분할 때 상수와 변수를 사용한다.
상수는 항상 같다. 항상 똑같은 변하지 않는 수를 말한다. 프로그램에서 한번 값이 대입되면 프로그램이 끝날 때까지 변하지 않는 속성이 있다.
반면 변수는 변하는 숫자이다. 프로그램에서 존재하는 순간부터 끝날 때까지 변할 수 있다.
상수가 정적인(static) 특성을 가지고 있다면,
변수는 동적인(dynamic)인 특성을 보여준다.
static이란 단어에 헷갈리면 안된다. 프로그래밍에선 문맥에 따라 달라지는 단어이다.
1. 숫자형 리터럴
숫자형 상수는 정수형과 실수형(부동소수점 방식)으로나눠진다.
리터럴은 literal 의 말 그대로, 있는 그대로의 뜻에서 나온 말이다. [literally 말그대로] 즉 숫자 있는 그대로이기 때문에 리터럴 상수라고 한다. const 로 선언하는 상수와 다르다.
아래 코드에서 정수형 a는 변수이고 7은 숫자형이자 정수형 리터럴 상수이다. 리터럴 정수이다.
b는 실수형 변수이고 0.98은 숫자형 길수형 리터럴 상수 이다. 리터럴 실수이다.
= 기호는 대입을 의미한다. 아래 코드는
1. 리터럴 정수를 정수형 변수 a 에 대입한다.
2. 리터럴 실수를 실수형 변수 b 에 대입한다.
int a = 7;
double b = 0.98;이렇듯 별 생각없이 입력하는 대입문도 컴파일러 입장에서는 각각의 타입에 대입이 가능한지 확인을 한 후 대입이된다.
실수형은 지수로 표현할 수도 있다. 1.7 e 100 은 10의 100승 곱하기 1.7을 의미한다. 100개나 되는 0을 컴퓨터에 쓰는 것보다 효율적이다.
double b = 1.7e100;
printf("%5.20e\n",b);
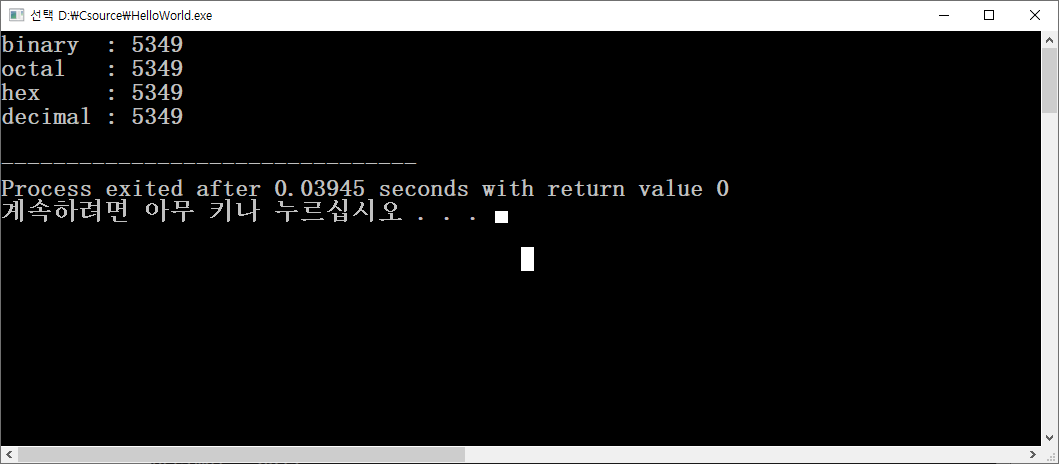
*이진법,8진법,16진법,10진법
#include <stdio.h>
int main(void){
int a = 0b001010011100101;
int b = 012345;
int c = 0x14E5;
int d = 5349;
printf("binary : %3d\n",a);
printf("octal : %3d\n",b);
printf("hex : %3d\n",c);
printf("decimal : %3d\n",d);
return 0;
} 진법의 차이에 대해서 알고 있다면 좋을 것이다. C언어를 배우는 것 자체가 하드웨어와 시스템에 대하여 알아가는 것이기 때문에 게을리 하면 뒤로 갈수록 힘들어진다.
2진법은 컴퓨터가 동작하는 원리 그 자체이다. 8진법은 비트 3개를 묶어서 변환이 쉽다. 2진수 비트 4개를 묶으면 16진수가 변환된다. 10진수만 가장 연결고리가 약하다. 2진 8진 16진법은 컴퓨터의 진법이라고 볼 수 있고 인간은 10진수를 쓴다.
printf 함수는 다른 진법을 사용해도 10진법으로 값을 변환하여 출력해준다. 숫자 앞의 prefix는 각 진법을 나타낸다.
8진수: 1 2 3 4 5
2진수: 001 010 011 100 101
2진수: 0001 0100 1110 0101
16진수: 1 4 E 5
10진수: 5 3 4 9 // 변환시에 별로 공통점이 없다.
2. 문자형 상수, 문자열 상수
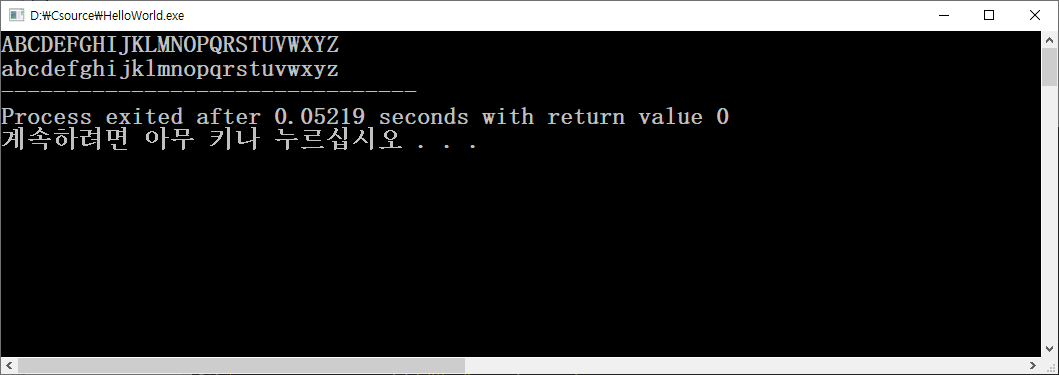
문자형 상수는 'A', 'B','C' 같은 문자 값을 말한다. * - + 등의 특수문자도 문자형 상수이다.
#include <stdio.h>
int main(void){
char index = 'A';
char lower = 'a';
int i;
for(i=0; i < 26; i++ )
{
printf("%c",index+i);
}
printf("\n");
for(i=0; i < 26; i++ )
{
printf("%c",lower+i);
}
return 0;
}
예제코드는 알파벳을 출력한다. 문자를 저장해도 내부적으로는 숫자로 저장되어있기에 연산이 가능하다.
문자형은 인간을 위한 것이다. 컴퓨터는 0과1밖에 해석하지 못한다. 반면 인간은 0과1은 알지만 기계어에 익숙하지 않다. 기계어란 인간에게 해독 불가는 아니지만 기계어로 컴퓨터를 사용하는 것은 비효율적이다.
아래의 x86 Instruction Set 의 OP 코드가 기계어이다. 16진수로 나타내었는데 실제 저장은 이진수로 되어있다. 그러니까 기계의 네이티브 언어란 것은 우리눈에 잘 들어오지도 않는다. 또 단순한 숫자의 나열이 아니라 언어이기 때문에 복잡한 문법이 존재한다.

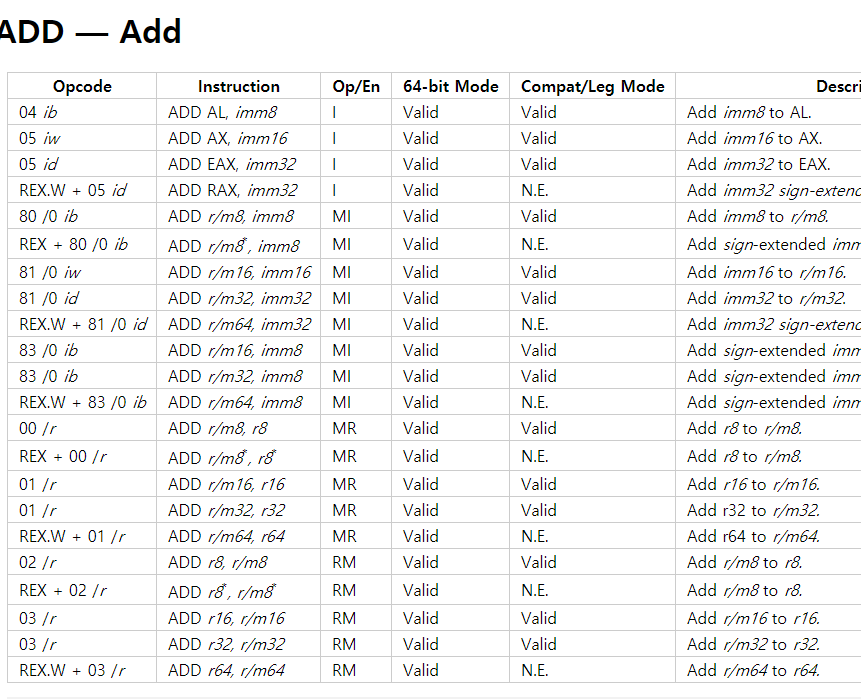
결국 문자열을 사용한다는 것은 변환과정에서 컴퓨터의 순수한 성능을 약간 떨어뜨릴 지라도 인간의 컴퓨터 사용을 최적화 시키기 위해서 인 것이다. 복잡한 아스키 코드나 유니코드도 인간과 기계 사이에 존재하는 것이다.
그러니까 문자형 상수는 문자인 동시에 숫자임을 알아두면 좋을 것 같다.
*문자열 상수는 문자형(문자 한개)을 여러개 이어붙인 것이다.
"Hello" 는 1바이트의 char 형 아스키 코드가 메모리에 5바이트를 차지하고 있는 것이다. 문자열은 배열을 다루는 법과 밀접한 관련이 있으므로 추후 상세하게 다루게 된다.
const 키워드
위에서 알아본 상수들은 리터럴이었다.
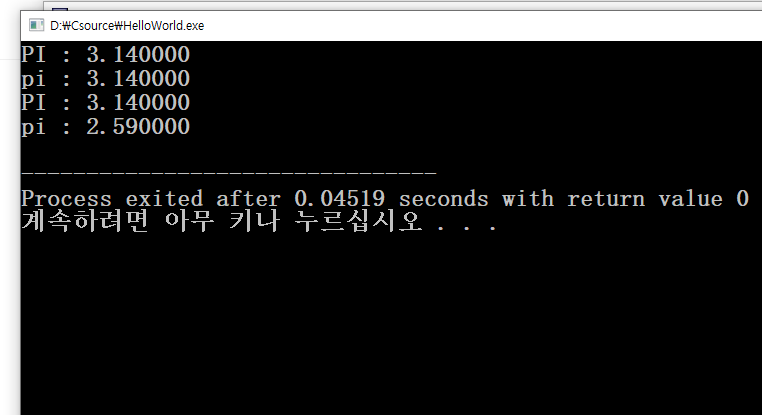
const는 식별자를 사용하여 상수를 사용하게 만들어 준다. const 키워드를 사용한 변수는 처음에 초기값을 대입한 후에 변경이 불가능하다. 대문자로 쓰는 것이 관례이다. 상수에 이름을 붙이는 것으로 생각하면 쉽다. 파이를 3.14라고 부르는 것 보다 파이라 부르는게 훨씬 다른 숫자들과 구분되고 의미가 있다.
#include <stdio.h>
int main(void){
const float PI = 3.14;
float pi = 3.14;
printf("PI : %f\n",PI);
printf("pi : %f\n",pi);
// PI를 수정하면 오류가 난다
// PI = 3.59;
pi = 2.59;
printf("PI : %f\n",PI);
printf("pi : %f\n",pi);
return 0;
} 
x86 인스트럭션
x86 and amd64 instruction reference
THIS REFERENCE IS NOT PERFECT. It's been mechanically separated into distinct files by a dumb script. It may be enough to replace the official documentation on your weekend reverse engineering project, but for anything where money is at stake, go get the o
www.felixcloutier.com