파이썬 정규식 4 | 정규식으로 클립보드에서 전화번호 추출하기 (치킨매장 번호)
클립보드에서 전화번호를 추출하는 것은 가장 정규식으로 할 수 있는 가장 보편적이고 간단한 작업에 속한다.
그렇지만 이 간단한 코딩으로도 복잡한 정규식에 대해서 자신감을 얻을 수 있다.
정규식은 텍스트의 패턴을 찾는 것이다.
물론 전화번호의 패턴은 생각했던 만큼 단순한 작업이 아닐 수 있다. 예를 들어 전세계 200개 나라의 모든 전화번호를 추출할 수 있는 정규식을 만들려고 하면 쉽지 않을 것이다. 한국 일본 중국 등 각 국가에 따라 전화번호 체계가 다르다. 다국어로 웹을 서비스하는 경우 이에 대한 대책이 있어야 할 것이다.
하지만 이 포스팅에서 하려는 것은 한국의 전화번호다. 휴대폰 번호와 가정용 전화번호의 조건으로 추출할 것이다. 정규식이 없이 코딩을 구현해본 사람들은 이것만으로도 정규식의 유용성을 느낄 수 있다.
다음 예제는 인터넷이나 다른 문서에서 Ctrl+C로 클립보드에 복사한 텍스트에서 전화번호를 추출하는 정규식이다.
import pyperclip
import re
phoneRegex = re.compile(r'''(
(\d{2,3})
(\s|-)
(\d{3,4})
(\s|-)
(\d{4})
)''',re.VERBOSE)
text = str(pyperclip.paste())
print(text)
match = []
list = phoneRegex.findall(text)
for g in list:
phoneNum = '-'.join([g[1],g[3],g[5]])
match.append(phoneNum)
with open('chickenstore.txt','w',encoding='utf8') as file:
for i in match:
file.write(i+'\n')
for i in match:
print(i)phoneRegex 인스턴스의 컴파일 부터 보자. 여러 줄 형식을 사용하려고 ''' 와 매개변수 re.VERBOSE 형식을 사용했다. 다른 기능이 아니라 코드의 가독성이 좋아진다. 위에서 부터 한줄씩 ()로 감싼 그룹으로 볼 수 있다.
1번 그룹은 숫자가 2-3개이다. 지역번호 앞자리 숫자 두개와 핸드폰 앞자리 세개가 해당한다.
2번 그룹은 공백이거나 (| 파이프) - 전화번호 이음 기호이다.
3번 그룹은 3-4개 숫자이다. 중간 번호에 해당한다.
4번 그룹은 2번 그룹과 형식이 같다.
5번 그룹은 마지막 네개 숫자이다.
클립보드에서 파이썬으로 텍스트를 가져오기 위해 pyperclip 모듈을 사용한다. 설치는 pip install pyperclip 이다.(윈10) 자세한 사항은 아래 포스트에 있다.
파이썬 모듈 pyperclip 으로 인터넷 자료 활용하기 | 텍스트 조작, 파일 저장 | 윈도우10 | 클립보드 �
파이썬으로 클립보드를 조작할 수 있는 모듈이다. 온라인 오픈소스 책인 invent with python 으로도 유명한 al sweigart 의 책에도 소개된 모듈이다. 간단하지만 업무자동화를 위해 유용하게 사용할 수 �
digiconfactory.tistory.com
findall 메소드로 리스트를 가져온다음에 문자열 - 클래스에서 join 한다. 1번,3번 5번을 그룹을 합치면 전화번호가 된다.
findall 로 생성되는 리스트는 아래처럼
('031-212-9293', '031', '-', '212', '-', '9293')
튜플로 분리된 그룹이다. 인덱스로 0,1,2,3,4,5 를 확인하면 1,3,5를 왜 다시 join 으로 묶는지 알 수 있다.
* 다음은 파일에 쓰기 모드로 기록한다. 여러 작업을 반복할 경우 add 모드로 기존 전화번호에서 추가시킬 수도 있을 것이다. 전화번호를 '\n' 개행문자나 다른 기호, 등으로 구분해주면 텍스트 파일의 가독성이 좋아진다.
*치킨 전화번호 추출하기
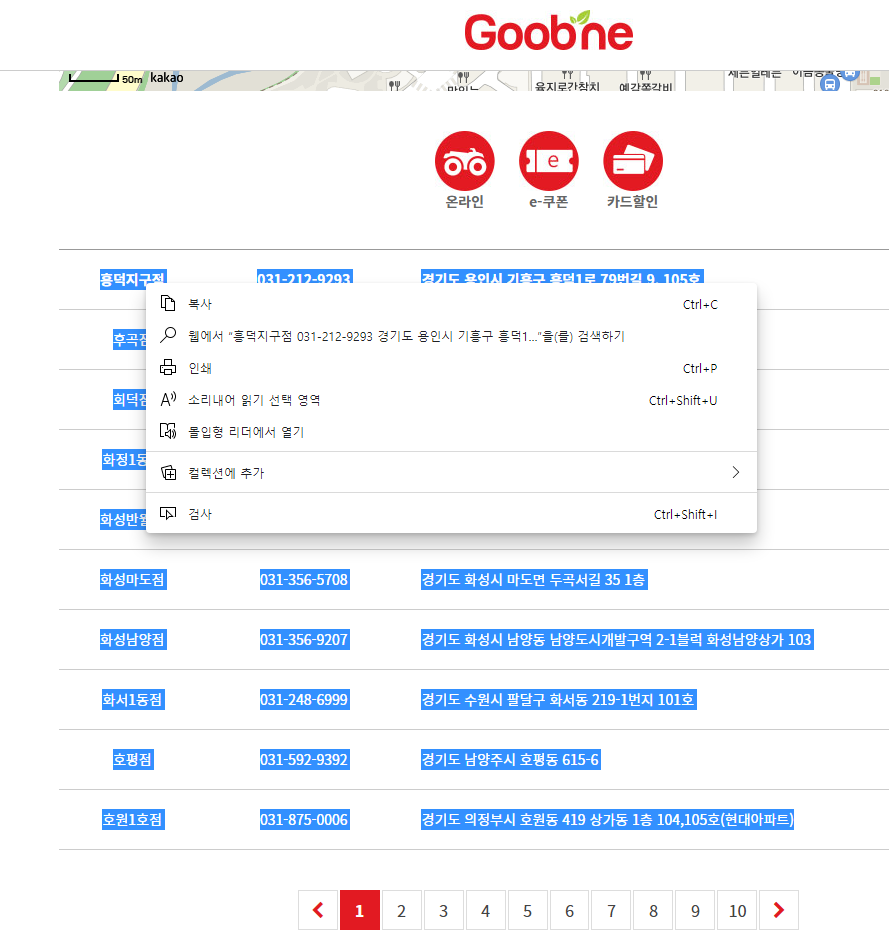
굽네치킨 홈페이지에 가서 전체 텍스트를 복사한다. Ctrl + C나 마우스 우클릭 -> 복사로 복사한다.

파이썬 스크립트를 실행한다. 당연하지만 이때 클립보드에 다른 것을 복사하면 안된다.
콘솔창을 통해서 전화번호만 추출되고 다른 텍스트는 사라진 것을 볼 수 있다.

텍스트 파일에도 저장이 잘 되었는지 확인한다. 'w' 모드로 새로열면 기존파일의 내용에 덮어씌워지니까 작업을 반복할 경우 반드시 add 모드로 열어서 작업한다.
*결론:
파이썬은 처음부터 이론적으로 파기 위한 언어가 아니다. 물론 파이썬도 심화이론으로 가면 어렵다. 모든 언어가 상중하 난이도가 있다. 위로 올라가면 계속 어려워진다. 단지 파이썬은 컴퓨터 공학 지식이 없어도 기능과 목적 위주로 쉽게 접근할 수 있기 때문에 실용적이다.
정규식은 매우 실용적인 형식언어이다. 위의 예제에서 뭔가 부족함을 느꼈다면 좋은 센스를 가진 것이다.
굽네치킨 홈페이지의 1000개 매장의 전화번호를 다 가져오는게 목적이면 좀 수고스럽다. 클릭, 드래그하고 복사하고 스크립트를 실행하는 과정이 반복되니 시간이 많이 걸릴 것이다. 한번에 10개 매장번호를 가져오니까 적어도 100번은 반복해야 한다. 그리고 매장의 이름을 꼭 가져와야한다. 이름과 전화번호만 알면 주소를 확인하는 것은 손쉬운 일이다. 전화를 해도 되고 인터넷에 검색만 해도 나온다.
정규식만 가지고는 한계가 있다.
이럴 때 필요한 것이 웹스크래이핑(크롤링)이다. 다행히 파이썬에는 다양한 모듈이 존재한다. 웹스크래이핑은 정규식과는 별개의 주제로 이 포스팅에서 다루지 않는다.
크롤링과 정규식을 함께 사용할 수 있다면 엄청난 자동화 도구를 손에 넣은 것이나 다름이 없다. 아침에 일어나 스크립트 실행 버튼을 누르는 것 만으로 실시간으로 업데이트된 액기스만 추출해서 자신의 피씨에 가져올 수 있다. 심지어 웹서비스에 개시하는 것도 가능하지만, 타인의 웹사이트를 무단 도용할 경우 저작권 문제로 크게 낭패를 볼 수 있다. 그러므로 웹에 개시할 때는 그 웹사이트와 기관의 허가를 받아야 한다. (비상업,상업 관계없다)
다만 순전히 개인적으로 사용하는 것은 인정이 되는 부분이 있다. 크롤링으로 지적 재산권 침해가 발생하고, 타인의 서버에 과도한 트래픽을 유발하는 경우 모니터링이 될 수 있다. 이중 삼중 보안접속을 해도 어쨋든 크롤링의 흔적이 남기 때문에 대체적으로 추적이 가능하다. 서버에 요청하는 절차와 속도가 인간과 다르기 때문이다. 그러므로 크롤링을 실행하기 전에는 주의가 필요하다.
(학습목적으로 구글이나 네이버에 한 두번 접속하는 것 정도는 괜찮은 것 같다)
*참고 포스팅: 크롤링 예제
파이썬 크롤링 (기상청 현재 날씨 정보 가져오기)
이번 포스팅에서는 파이썬 크롤링을 정리해본다. 이 내용은 파이썬 코딩도장의 책 내용을 따라 실행하면서 겪은 과정에 대한 설명이다. 파이썬 코딩 도장은 초판이 발행된지는 몇년되었지만 코
digiconfactory.tistory.com
다시 치킨 전화번호로 돌아가서 굽네치킨의 웹사이트를 크롤링하여 html 파일을 가져온 후 parsing 한 후, 그 내용물들을 정규식으로 정밀하게 조작할 수 있다. 엑셀파일에 데이터를 정렬시키는 일까지 파이썬으로 다 가능하다. 그러니까 정규식은 조금 부담스러운 문법이 들어가지만 텍스트 정보처리를 다루기 위해서는 꼭 알고 있어야 하는 기술이다.