파이썬 정규식 1 | 숫자 패턴 찾기
정규식(Regular Expression)은 특정한 규칙을 가진 문자열의 집합을 표현하는 데 사용하는 형식언어이다.
처음 듣는 사람에겐 개념도 어렵다. 정규식이 사용되는 쉬운 예를 들면 워드나 인터넷 프로그램에서 Ctrl-F를 눌러서 원하는 글자를 찾아본 경험이 있을 것이다. 글자만 타이핑 해도 쉽게 찾아지는 것은 정규식을 사용하기 때문이다.
정규식은 특정한 언어에만 사용할 수 있는 것이 아니다. 특정한 시스템 운영체제에서 동작하는 언어가 아니라 텍스트를 처리하는 범용 형식언어임에 주의한다. 자꾸 언어라고 하면 헷갈린다.
정규식은 텍스트(문자열이 여럿 모인 것)안에서 패턴을 찾아서 처리하는데 특화한다. 어느 컴퓨터에나 텍스트(즉 문자열이 모인 덩어리, 파일)는 존재한다. 인간이 보는 것은 텍스트이기 때문이다.
지금까지 컴퓨터를 배우면서 0과1에 대해서 공부해왔다면 기계의 소통방식을 이해할 것이다. 정규식은 컴퓨터에서 동작하는 인간의 언어이다. 알 스웨이가트의 '파이썬 프로그래밍으로 지루한 작업 자동화하기' 책에서는 정규표현식을 안다는 것은 문제를 3단계로 해결하는 것과 3,000단계로 해결하는 것 만큼이나 차이가 있을 수 있다고 한다.
3000단계면 거의 1000배나 차이가 나는데?? 프로젝트의 크기가 커지면 커질 수록 정규식의 이점이 배수로 늘어난 다는 것을 설명하는 것으로 보인다. C에서 자바, 자바에서 파이썬으로 넘어가며 코딩을 하다 보면, 점점 기계와 기능 중심에서 인간과 프로젝트 중심으로 바뀌는 느낌이다.
정규 표현식 - 위키백과, 우리 모두의 백과사전
위키백과, 우리 모두의 백과사전. 노랑색 강조 부분은 다음 정규식을 사용했을 때 매치된 것이다. 정규 표현식(正規表現式, 영어: regular expression, 간단히 regexp[1] 또는 regex, rational expression)[2][3] 또
ko.wikipedia.org
하드웨어와 소프트웨어 기술이 발달할 수록 인간과 기계의 인터페이스가 더 개선된다. 조금의 코드로도 다양한 프로그램을 만들 수 있는 파이썬이 대표적이다. 인간은 열심히 아이디어를 짜서 실현시키면 된다. 정규식은 그런 환경에서 인간에게 날개를 달아주는 언어이다.
정규식은 텍스트 패턴을 찾기 위한 언어이다. 그런데 프로그래밍 언어의 원초적 기능만으로도 텍스트 패턴을 찾는 것은 가능하다.
정규식 학습을 들어가기 이전에 시험적으로 문자열의 패턴을 찾는 프로그램을 만들어본다. 파이썬의 코드와 C나 자바 등 다른 언어와 차이가 있다. 그리고 같은 파이썬 코드라도 차이가 있다는 점을 생각한다.
다음 예제는 문자열에서 0부터 9까지의 숫자를 추출해본다.
text = input("Enter some string : ")
numberString = []
i=0
while i < len(text):
ch = text[i]
if ord(ch) == ord('0') or ord(ch) == ord('1') or ord(ch) == ord('2') or ord(ch) == ord('3') or ord(ch) == ord('4') \
or ord(ch) == ord('5') or ord(ch) == ord('6') or ord(ch) == ord('7') or ord(ch) == ord('8') or ord(ch) == ord('9'):
print(ch + ' is a digit')
numberString.append(ch)
else:
print(ch + ' is not a digit')
i += 1
print()
print(numberString)
print("END")
결과창은 아래와 같다. 사용자로 부터 문자열을 입력받아서 숫자를 골라낸다. 키보드에서 받은 문자열은 아스키 코드로 저장된다. 문자열에서 숫자를 골라내기 위해서는 아스키 코드로 비교를 해야한다.
(영문) ord() 메소드는 아스키 문자를 정수값으로 변환한다. '0' 은 16진수 0x30 이고 십진수로 48이다. while 문으로 텍스트에 들어있는 문자를 하나씩 가져와서 비교한다. 0에서 9까지 일치하면 digit 으로 처리하고 리스트에 추가한다.
아래의 결과를 보면 공백 ' ' 도 비교하는 것을 볼 수 있다. 눈에 보이는 문자는 없으나 공백도 문자이다. 키보드의 특수문자에도 각각의 아스키 코드가 들어있으니 위의 숫자를 추출하는 것처럼 뽑아낼 수 있다.
Enter some string : number 1 and 2 is faster than %$#@@^. we know this 99% for sure.
n is not a digit
u is not a digit
m is not a digit
b is not a digit
e is not a digit
r is not a digit
is not a digit
1 is a digit
is not a digit
a is not a digit
n is not a digit
d is not a digit
is not a digit
2 is a digit
is not a digit
i is not a digit
s is not a digit
is not a digit
f is not a digit
a is not a digit
s is not a digit
t is not a digit
e is not a digit
r is not a digit
is not a digit
t is not a digit
h is not a digit
a is not a digit
n is not a digit
is not a digit
% is not a digit
$ is not a digit
# is not a digit
@ is not a digit
@ is not a digit
^ is not a digit
. is not a digit
is not a digit
w is not a digit
e is not a digit
is not a digit
k is not a digit
n is not a digit
o is not a digit
w is not a digit
is not a digit
t is not a digit
h is not a digit
i is not a digit
s is not a digit
is not a digit
9 is a digit
9 is a digit
% is not a digit
is not a digit
f is not a digit
o is not a digit
r is not a digit
is not a digit
s is not a digit
u is not a digit
r is not a digit
e is not a digit
. is not a digit
['1', '2', '9', '9']
END
숫자를 분리해서 리스트에 저장했지만 이들은 각각 하나의 문자로써 저장된다. 원본 숫자를 추출해서 정수로 사용하기 위해서는 추가적인 로직이 필요하다. 하나의 기능을 추가하려면 그에 따라 코드가 복잡해질 것이다.
위의 예제는 예를 들어 작성한 코드다. 정규식 없이도 텍스트 패턴을 찾는 것은 가능하다는 것을 말한다. 그런데 이런 언어 공통의 문제를 각각의 프로그래머가 매번 작성하는 것은 비효율적이다. 대부분의 프로젝트에 텍스트(문자열)에 대한 처리는 필요하다. 웹사이트는 말할 것도 없다. 다행히 파이썬에는 프로그래머들의 효율을 올려줄 정규식 라이브러리가 들어있다.
파이썬의 re 라이브러리를 사용해 보자.
import re
phoneNumRegex = re.compile(r'(\(\d\d\d\))-(\d\d\d\d)-(\d\d\d\d)')
mo = phoneNumRegex.search('내 전화번호 (010)-1111-2222')
print('전화번호 전체 : ' + mo.group(0))
print('전화번호 앞자리 : ' + mo.group(1))
print('전화번호 중간 : ' + mo.group(2))
print('전화번호 뒷자리 : ' + mo.group(3))
print(mo.groups())
base, number1, number2 = mo.groups()
print(base)
print(number1)
print(number2)
정규식을 사용하면 단번에 전화번호가 추출된다.
re 모듈은 파이썬에 기본으로 설치된다. re 는 regular expression 의 약어이다.
re.compile 에는 정규식을 컴파일 한다. \d 는 숫자 한자리다. \d\d\d 로 010 을 추출할 수 있다. ( ) 그룹으로 묶으면 ( )로 구분되는 요소들의 리스트를 만들어준다. r ' 문자열 '은 raw string 원시 문자열을 의미한다. 일반 문자열 처럼 이스케이프 문자열을 취급하지 않는다. 그리고 앞쪽에 \는 이 다음에 오는 문자에 따라 정규식의 문자 클래스가 결정된다. \d는 숫자 0-9를 의미한다. 위의 숫자 추출 예제에서 본 조건식이 하나의 문자에 담겨있다고 보면 된다.
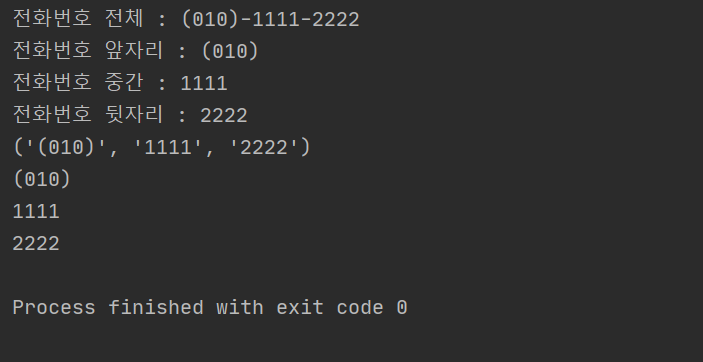
mo 인스턴스에서 group 의 인덱스를 보면 의미를 알 수 있다. 전체, 첫번째, 두번째... 이렇게 찾은 문자 패턴의 개수에 따라서 정해진다.
앞쪽의 코드와 비교하면 알 수 있지만 훨씬 코드가 간결하고 몇줄 안되는 코드로 많은 일을 할 수 있다. 정규식에는 이것 뿐 아니라 더 강력한 기능들이 들어있다. 차근차근 알아가 볼 것이다.
아래 웹사이트는 온라인상에서 정규식을 테스트 해볼 수 있는 사이트이다. 자바스크립트 기반으로 파이썬과는 차이가 있다. 그러나 원리는 같으니까 어떻게 작동하는지 궁굼하면 텍스트를 끌어다 놓고 이것저것 해볼 수 있다. 인터넷 주소 검사등 여러가지 예제가 나와있으니 한번 테스트해보는 것도 도움이 될 것이다.
Regex Tester - Javascript, PCRE, PHP
RegexPal requires a modern browser. Please update your browser to the latest version and try again.
www.regexpal.com

*참고 인터넷 주소 유효성 검사하기, 정규식
*참고 아스키 코드
C언어 2 - 2 | 자료형 | 아스키코드
C언어에 대한 내용을 다룰 때 아스키 코드에 대한 이야기를 하려고 생각하고 있었다. 다행히 요즘은 인터넷에 아스키 코드에 관해서는 쉬운 설명도 많이 있고 한글 자료도 많다. 아스키코드는 ��
digiconfactory.tistory.com