주소지정방식 (addressing mode) 조작하기 - NASM x86_64 어셈블리어 11
주소지정방식은 컴퓨터 구조에서 이론으로
배우는 내용이긴 합니다만, 대충 봤을 때
이론적으로 배워도 별 소용이 없는 내용입니다.
다양한 주소지정방식(addressing mode)이 있는데
8086 명령어는 유연성을 제공하는 시스템이라서
핵심은 프로그래머가 최적의 주소지정방식을
선택할 수 있는가 혹은 없는가가 중요합니다.
C언어의 창시자인 데니스 리치도 C언어에서
프로그래머의 권한과 책임에 대해서
고수준에서 최대한 보장하도록 만들었는데요,
이런 아이디어는 초기 x86 CPU의 설계자들도
가지고 있었다고 볼 수 있습니다.
Addressing Modes에 대한 자료를 체크하면
어떤 포커스가 있습니다. CPU 명령어(instruction)를
어떻게 사용하면 가장 효율적일까 - 에 초점이
맞춰져 있습니다. CPU설계에 Risc가 좋냐
Cisc가 좋냐를 따지는데, 이는 현대 CPU설계에서
끓이지 않는 논쟁꺼리이기도 합니다.
좀더 쉽게 이야기한다면 주소지정방식에 따라
CPU의 명령어(instruction) 동작에 큰 차이가 납니다.
우리가 봤을 때는 큰 차이가 아닌 동작도
1초에 기가 단위로 동작하는 CPU적인
결과로는 엄청난 차이가 나는 경우가 있습니다.
특히 CPU가 사용하는 데이터는 레지스터, 캐시,
메모리, 드라이브의 최소 4단계를 거치므로
이 네 군데 중 하나에서 데이터를 가져와야
하는 CPU 입장에서는 상당한 고민이 됩니다.
접근 속도의 차이는 다음과 같습니다.
레지스터 > 캐시 > 메모리 > 드라이브
주소지정방식에서는 주로 레지스터인지
메모리인지에 대해서 포커스를 맞추고 있습니다.
아무래도 캐시는 하드웨어와 운영체제가
담당하고 있고 드라이브에서 메모리로
가져오는 일도 현대 프로그래밍에서는
소프트웨어적인 부분은 별로 없기 때문입니다.
어셈블리어를 사용할 때는 이런 것들을
이해해는게 중요합니다. C언어만 해도
컴파일러가 최적화 해서 처리해주는
부분들인데 어셈블리어는 밑바닥이라서
이런 것들을 알아서 해야 합니다.
그렇다고 주소지정방식을 너무 심각하게
생각할 필요까지는 없다고 봅니다.
왜냐하면 지금 시점에 어셈블리어로
작성하는 부분은 특정 모듈 정도로
봐야 하기 때문에 그 정도로 복잡한 경우가
많지는 않을 것이라 볼 수도 있습니다.
이 포스팅에서는 이론적인 내용보다는
실제적인 코드의 실행을 실습합니다.
쨋든 실제적으로 느끼고 사용하는게 중요합니다.
명령어의 주소 모드
이것을 자꾸 이론적으로 어렵게 생각하면
오히려 프로그래밍에는 방해가 될 수도 있습니다.
간단하게 생각하면,
mov rax, 1
이 명령어는 CPU가 메모리에 접근할 필요가
없습니다. CPU가 레지스터에서 접근하는 것은
메모리보다 100배 이상 빠릅니다.
var1 이란 변수에 1이란 숫자를 입력한다면
rax 레지스터에 1을 입력하는 것보다 100배
이상의 시간이 소요될 수 있습니다.
CPU의 클럭 개념에서 보면 현대의 3기가 CPU는
명령어(instruction)을 초당 30억번 이상 실행할 수
있기 때문에 이것들을 우리가 체감할 정도는 아닙니다.
그냥 수학적인 이성의 영역이지요. 이성적인 영역은
알면 좋고 몰라도 상관은 없습니다. 적어도
우리가 몰라도 인생에 딱히 지장이 없습니다.
CPU의 이해 / CPU의 속도 - 컴퓨터 기초 교양 1 (tistory.com)
CPU의 이해 / CPU의 속도 - 컴퓨터 기초 교양 1
CPU의 이해 이번 포스팅에서는 CPU에 대해서 간단히 살펴보겠습니다. 또 컴퓨터 시스템에서 상당히 어려운 주제의 하나인 CPU의 속도에 대해서 다루어 보겠습니다. CPU는 Central Processing Unit - 중앙처
digiconfactory.tistory.com
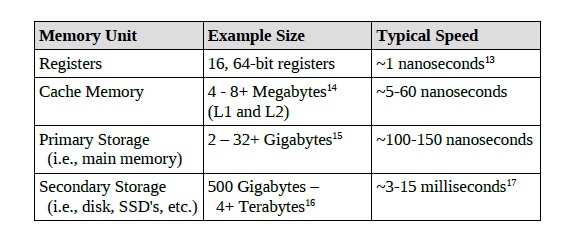
복잡하게 보여도 기본은 빠른 저장장치를 써야한다.
그런데 빠를 수록 비용이 비싸고 용량이 적다 -
그런 tradeoff 가 있다만 알면 원리는 명확합니다.
범용 레지스터는 16개입니다.
64비트는 rax부터 r15까지 있습니다.
이것만 쓰면 너무 짝지요.

해서 메모리를 써야하는데 메모리를
사용하려면 변수를 만들어야 합니다.
이런 본질적인 부분이 인간에게 프로그래밍을
어렵게 만드는 부분입니다.
그 내용을 약간 더 이해하면 별것도
아닌 원리에 많은 시간을 허비해야 하는
단계가 현재의 IT교육 시스템이 아닌가
조금 의문을 품을 수도 있습니다.
최근에 이 IT짭블로그에서 종종 이야기 하는데
요새 '누구나 코딩' 같은 마케팅이 성행하는 것에
대해서 비판적인 의견을 가끔 합니다.
프로그래밍은 재능이 있는 사람과
재능이 없는 사람이 갈립니다.
뭐랄까... 이 세상 거의 모든 직업에는
직업의 차이가 있을 수 있다고 봅니다.
이렇게 꼬아서 말하는 이유는
순전히 세상의 편견 때문입니다.
편견은 극복할 수 있는 대상이 아닙니다.
그것은 인간의 불치병인 암이나 에이즈 처럼
함께 달고 살아야 하는 것 입니다.
편견과 싸우는 이는 항상, 뭐 이기는 경우도
가끔은 있긴 하지만 끝의 말로가
항상 좋다고 말하기는 어렵습니다.
편견은 나쁜게 아니라 그냥 세상을
살아가는 사람들의 흔적이기 때문입니다.
이것을 두고 평가하고 결론을 내면
거기가 싸움장일 뿐입니다.
프로그래밍은 재능의 영역입니다.
그것이 노력의 결실이든 천부적인
능력의 결과이든 본질은 재능입니다.
드롭박스의 창업자 드루 휴스턴은
일찍이 성공해서 한 말이 있는데
프로그래밍은 피아노와 비슷하다고 합니다.
수많은 시간을 바쳐서 연습을 거듭한 후에
제대로된 작품이 나온다고 합니다.
(물론 그는 어렸을 때부터 빌게이츠 같은 천재 부류였다)
피아노에 비유를 한 것은 피아노를
수천번 쳐도 피아니스트로 남는 것은
아주 극소수에 불과하기 때문입니다.
이것은 대충 대학을 졸업해서 취직하는
직장인들과 같지가 않지요.
생과사를 몇번 가른 후에 남은 이들이
우리가 알고 있는 피아니스트가 됩니다.
그래서 우리는 그들의 음악세계를
인정하는 것이고 기준은 높을 수 밖에 없습니다.
피아니스트가 음정을 틀린 다는 것은
약간 죄악에 가까운 일이지요.
그래도 피아니스트는 억울해 하지 않습니다.
피아니스트는 일반 직장인이 아니니까요.
이건 너무나 당연한 일인데 만일
프로그래머를 비유한다면 그 사람이
자신은 프로그래머 이전에 9 to 6 근로자가
더 중요한 가치라면 그에는 좀 더
가혹한 일이 될 수 있습니다.
아니 코드 하나 비효율적인게 무슨 죄인가?
(뻑나면 잘못이긴 하다)
약간 삼천포로 세는 느낌이 들지만
프로그래밍도 피아니스트와 본질은
같지 않나 그런 생각을 해봅니다.
지금은 100% 맞지 않는데
언젠가 미래 사회의 시민이 코드에서
피아노의 음정을 느낄 정도가 되면
그런 날이 올수도 있다고 봅니다.
피아노나 음악도 불과 1-2세기 전에는
귀족들의 고귀하고 사치적인 부분이었습니다.
미래에는 프로그래밍의 논리가
그런 역할을 할 수도 있지 않을까
이건 순전한 상상입니다.
*뭐 좋습니다. 오늘은 너무 잡설을 많이 했는데
어차피 어셈블리어 포스팅 11 같은 것은
정말로 매우 극소수만 보기 때문에
열심히 작성하지는 않습니다.
그리고 어셈블리어를 배우다가 여기쯤
올라오기 전에 대부분 포기하기 때문에
더욱 검색될 일이 많지는 않은 포스팅입니다.
*주소지정모드 이유
주소지정모드 이유는 아키텍쳐의 효율성입니다.
CPU입장에서는 당연히 뭐든 빠른게 좋습니다만,
모든 명령어가 빠를 수 없습니다.
해서 선택을 해야 하는데
CPU가 입력받는 건 기계어기 때문에
기계어는 0과 1입니다. 0과1을 늘릴 것인가
줄일 것인가 아키텍쳐의 주소지정모드에 달려있습니다.
기본은 세개의 모드입니다.
1. 레지스터(Register)
2. 즉시값(Immediate)
3. 메모리(Memory)
레지스터는 어셈블리어의 기본 단위입니다.
어떻게 보면 어셈블리어를 사용하는 이유는
레지스터에 접근하기 위해서입니다.
2번 즉시값이나 3번 메모리는 고수준 언어
(high-level language)에서도 다 쓸 수 있습니다.
Nasm 문법에서는
mov rax, 1
레지스터 rax에 즉시값 1을 할당합니다.
rax에 할당하는 것은 [값]입니다.
그럼 변수는 어떨까요?
변수는 레지스터가 아니라 메모리입니다.
section .data 에서 var1: dq 10이라면
var1의 값을 rax 에 입력하려면
mov rax, [var1] 입니다.
왜냐하면 mov rax, var1 은
var1변수의 메모리 주소를
rax에 입력하기 때문입니다.
[var1]은 C언어의 포인터 역참조(dereference)
개념으로 var1 이 가진 메모리 주소에 있는
값을 가져옵니다. 즉 rax에는 var1 변수의
값이 저장됩니다. 고수준 언어에 익숙하면
Nasm 어셈블리어를 시작할 때 어렵게
느낄 수 있는 부분입니다. var1을 변수로
선언하면 var1은 메모리 주소 [var1]이
역참조 입니다. 레지스터는 그렇게 없습니다.
mov rax, 1 은 직관적으로 rax 레지스터에
숫자값 1을 넣습니다. 어셈블리어 문법에
익숙하려면 첫번째로 레지스터와 변수의
주소지정방식을 구분할 것 - 입니다.
예제 - 변수의 주소지정
어셈블리어를 컴파일 하다보면 조금
복잡한 규칙을 알 수 있습니다.
C같은 고수준 언어에서는 조금 더
쉬운 것들이 당연하지 않습니다.
메모리 맵핑에 대해서 이해할 필요가 있는데
메모리 주소는 숫자입니다.
32비트의 경우 16진수로
0x0000 0000 ~ 0xFFFF FFFF
라고 표기합니다. 이 표기법이 표준인데
평생 10진수를 써왔던 우리들에게는
좀 불편한게 정상입니다.
16진수로 표기하는 이유가 0과1을
단위로 하는 2진수 체계를 확장해서 보면
16진수가 더 쉽기 때문인데 10진수에
익숙한 사람들에게는 이해가 되지 않습니다.
해서 컴퓨터 구조를 알려면 다른 것보다
우선 2진수 시스템이 어떻게 16진수로
확장되는지 훈련을 할 필요는 있습니다.
16진수에 대해서는 다른 포스팅에서
좀 더 다루어 보기로 하고 메모리 맵핑은
어떻게 되는가? 에 초점을 맞춰 보겠습니다.
메모리의 주소는 사람들이 사는 일반
주소와 크게 차이가 없습니다.
차이가 있다면 0번지를 쓰는 건데
0은 컴퓨터에서 실제적인 값이라서 그렇습니다.
주소에서는 0번지 같은 것을 잘 안씁니다.
예를 들어 아파트를 보면 3층 1호라고 하지
3층 0호라고는 잘 안합니다.
(그렇게 붙일 수 있음에도 불구하고)
0을 다루는 시각이 컴퓨터와 현실의
차이에 있긴 합니다. 0에 대해서 좀더
생각할 꺼리는 아래 포스팅에 있습니다.
중학수학 | 0이란 무엇인가? | 0의 리뷰
0은 무엇인가? 수의 세계에서 0은 특별한 위치를 갖고 있습니다. 현대인은 0의 개념을 무리없이 받아들이지만 0이 발견된 것은 5세기경 인도에서 사용하기 시작했다고 합니다. 그러니까 그 전에 0
digiconfactory.tistory.com
메모리 맵핑은 간단합니다.
사용을 좀 복잡하게 해서 그렇지...
0x0000 0000 ~ 0xFFFF FFFF
는 32비트 주소입니다. 메모리의 숫자
0x0000 0000 이 의미하는 것은 1바이트입니다.
1바이트는 2의 8승으로 256 표현이고
2진수로 0000 0000 ~ 1111 1111
로 나타냅니다. 즉 메모리 0x0000 0000~
0xFFFF FFFF 는 256 x 4,294,967,296 입니다.
256의 숫자를 42억개 표현할 수 있고
경우의 수로는 1,099,511,627,776니까
약 10조개가 나옵니다. 32비트만 해도
엄청난 숫자인데 감이 잘 오지 않습니다.
메모리를 바이트 단위로 Access 한다는
개념은 컴퓨터 소프트웨어를 다루는데 있어서
어떻게 보면 가장 중요합니다.
Nasm에서 64비트 레지스터는 이보다
더 큰 64비트의 메모리 주소를 조작할 수
있는데 이는 당연하게도 32비트인 eax
레지스터보다 비트가 32개 많아서입니다.
2의 64승은 18,446,744,073,709,551,616 인데
발음하는 것도 잘 모르겠습니다.
그 정도의 메모리를 쓸 프로그램은 21세기
초기라도 별로 없기 때문에 대부분의
프로그램은 32비트에서 잘 돌아갑니다.
다음의 코드는 var1의 값과 주소를
사용하는 방법입니다.
var1 변수는 [] 없이는 주소입니다.
여기서 printInt는 C언어 라이브러리
printf 를 사용한 정수값을 출력합니다.
section .data
var1 dq 777
section .text
mov rax, qword [var1]
printInt rax ;print variable value
mov rax, var1
printInt rax ;print address of var주소값은 10진수인데 시스템에 따라 다를 수 있습니다.
(WSL2 우분투에서 실행)
- value: (777)
- value: (4210810)dq 는 define quad word 이고 64비트 입니다.
qword [var1]은 64비트를 rax에 대입합니다.
만약 mov eax로 하면 에러가 나는데
32비트에 64비트인 quad word 값은 할당이 안됩니다.
한편 var1은 64비트 주소이므로 rax에
자연스럽게 할당이 됩니다.
따라서 [] 없이는 주소값이 출력됩니다.
배열(Array)의 주소
C언어나 다른 언어에서 배열을 배웠을 겁니다.
보통 배열은 바이트값의 나열입니다. 예를 들어
myArray: dd 100, 200, 300, 400, 500
이라면 myArray란 배열의 이름으로
double word(32bit)의 숫자 다섯개를
메모리에 할당합니다.
이것들은 지금 메모리에 들어가 있는데
어떻게 접근하느냐? - 문제가 있습니다.
C언어를 안다면 좀 더 쉽게 이해할 겁니다.
위에서 변수의 이름은 주소라고 했습니다.
메모리의 주소입니다. 배열은 상대주소입니다.
myArray의 주소를 4000 0000 이라고 합시다.
그러면 첫번째 주소에는 100 이 들어있습니다.
이는 [myArrary] 입니다. 이 숫자를 쓰려면
[]을 하던가 레지스터에 옮겨서 씁니다.
mov rax, [myArray] 처럼 됩니다.
그럼 배열의 다음 요소에 접근하고 싶다면?
double word 라고 했습니다. 이는 4바이트이지요.
그럼 myArray+4는 4000 0004가 됩니다.
여기에 저장된 quad word값은 200 입니다.
C언어의 포인터를 아는 사람은
이게 무슨 의미인지 단번에 파악할 수 있습니다.
그 다음 요소에 접근하려면 4바이트를
더해주면 됩니다. myArray+8이지요.
여기서 요소를 봤을 때 4라는 것은
displacement 라고 하며 index는 요소의
순번입니다. 첫번째 요소는 0이고 그 다음은
1,2... 이렇게 갑니다. 그렇지요. C언어에서
봤던 index 방식 myArray[0], myArray[1]
이것은 discplacement를 인덱스에
곱하는 방식입니다. 이걸 알면 메모리를
상당히 깊이 있게 파고들은 것 입니다.
뭐 이런걸 딱히 몰라도 상관은 없습니다만,
이게 데이타 구조나 알고리즘의 밑바닥을
그나마 쉽게 설명하는게 아닌가 - 그런
합리적 의심을 해봅니다. 어떻게 돌아가는지
밑바닥을 알고 있으면 컴퓨터는 점점 더 쉬워지는데
현대의 컴퓨터 교육은 자꾸 이런 것을 피해가니까요.
요새는 포인터를 배우는데 어셈블리어까지
알 필요는 없지만 원리가 그렇습니다.
거꾸로 어셈블리어를 알면 포인터는
이미 알고 있는 것과 마찬가지라서
그것은 학습자의 재량에 달려 있습니다.
한편으로 이런 것들을 몰라도 프로그래머로
밥먹고 사는데는 전혀 지장이 없으니까
혹시라도 걱정할 필요는 없습니다.
이 포스팅은 오로지 설명 그 자체에 목적이 있습니다.
인터넷에 수많은 문서가 있는데
아직 조금 부족한 것 같으니까요.
예제 코드
아래의 예제 코드는 위의 내용을 이것저것
조작해보기 위해 만든 튜토리얼입니다.
주소지정모드는 규칙이 까다로와서
정확히 지정할 필요가 있습니다.
예를 들어서 mov eax, qword [var1]
같은 건 안되는데요. qword는 64비트인데
eax는 32비트입니다. 32비트가 초과하므로
할당이 불가능합니다. 그것 말고도 여러가지
제한사항이 있으니까 디버그 하면서
뭐가 되는지 뭐가 안되는지 규칙을 깨달을
필요가 있습니다. 머리로 아는 것만으로는 부족한데
드롭박스 창업자의 말처럼 실습을 해야 합니다.
남의 코드를 백날 봐봤자 별 소용이 없는 것은
악보를 백날 봐도 제대로 연습을 하기 전까지는
연주를 못하는 것과 같습니다. 간단한 원리지요.
it's that simple. everybody knows.
extern printf
%macro printInt 1
mov rsi, %1
call _printfInt
%endmacro
%macro printStr 1
mov rsi, %1
call _printStr
%endmacro
section .data
textTitle: db 10,"[-- NASM Assembler Basics --]",10,0
textSubtitle: db "- Addressing Modes -",10,10,0
intFormat: db "- value: (%ld)",10,0
strFormat: db "%s",0
var1 dq 777
var2 dq 12
var3 dq 1500
myArray dd 100,200,300,400,500
myNewByte db 123
someMemory db 0
section .text
global main
main:
nop ;just a placeholder
printStr textTitle
printStr textSubtitle
;**********************************
;--------- variable usage ---------
mov rax, qword [var1]
printInt rax ;print variable value
mov rax, var1
printInt rax ;print address of var1
;**********************************
;--------- variable usage ---------
printInt myArray
printInt myArray+4
printInt myArray+8
printInt myArray+12
printInt myArray+16
printInt myNewByte
; mov eax, dword [myArray]
mov rbx, myArray
mov eax, dword [rbx]
printInt rax
xor rax, rax
mov rbx, myArray+4
mov eax, dword [rbx]
printInt rax
mov rbx, myArray+8
mov eax, dword [rbx]
printInt rax
; same result
mov eax, dword [myArray+12]
printInt rax
mov eax, dword [myArray+16]
printInt rax
mov eax, dword [myArray+20]
printInt rax
; same address
mov eax, dword [myNewByte]
printInt rax
;use a base address
mov rbx, myArray
mov rsi, 8 ;displacement (offset)
mov eax, dword [myArray+8]
printInt rax
mov eax, dword [rbx+8]
printInt rax
mov rsi, 8
push rsi
printInt rsi
pop rsi
mov eax, dword [rbx+rsi]
printInt rax
xor rax, rax
inc rax
printInt rax
mov [someMemory], byte 1
mov rax, [var1]
printInt rax
nop
_last:
mov rax, 60
mov rdi, 0
syscall
_printfInt:
push rbp
mov rdi, intFormat
; mov rsi, rax
mov rax, 0
call printf
pop rbp
ret
_printStr:
push rbp
mov rdi, strFormat
mov rax, 0
call printf
pop rbp
retall:
nasm -g -f elf64 -F dwarf -o main.o -l main.lst main.asm
gcc main.o -o main -no-pie
./main
정리
주소지정모드를 너무 복잡하게 이론화해서
거부감이 있는데 여기서는 실제적으로
적용가능하도록 좀 들여다 봤습니다.
이 원리는 간단합니다. 레지스터를 최대한
사용하면 좋습니다. 하지만 레지스터의
개수가 너무 적지요. 컴파일러는 최대한
레지스터를 사용하도록 최적화합니다.
그게 빠르기 때문입니다. 어셈블리어
프로그래머라면 적어도 이 tradeoff를
풀려고 개기는 노력이 필요합니다.
그게 주소지정모드의 본질이 아닐까 -
아쉬움이 남습니다.
https://en.wikipedia.org/wiki/Addressing_mode
Addressing mode - Wikipedia
From Wikipedia, the free encyclopedia Jump to navigation Jump to search Aspect of the instruction set architecture of CPUs Addressing modes are an aspect of the instruction set architecture in most central processing unit (CPU) designs. The various address
en.wikipedia.org