자바 튜토리얼 12 - 6 | HashSet | 컬렉션 프레임워크 |
HashSet 클래스는 Set 인터페이스를 구현한 컬렉션이다.

Set (집합) 인터페이스의 특징은 중복된 요소를 저장하지 않는다는 점이다.
중복을 피하는 자료형태를 선택할 때 HashSet 을 사용할 수 있다.
수학의 Set (집합)에서 중복을 허용하지 않는 것과 같은 원리지만 약간 차이가 있다.
import java.util.HashSet;
import java.util.Iterator;
import java.util.Set;
public class Main {
public static void main(String[] args) {
Object[] array = {"99", 99, 99, "5", 5, "5", "7", "7", "7", "2", "3", "3", "2"};
Set set = new HashSet();
for (int i = 0; i < array.length; i++) {
set.add(array[i]);
}
//HashSet
System.out.println(set);
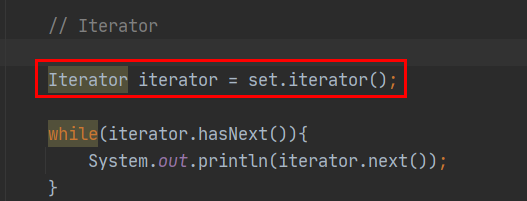
// Iterator
Iterator iterator = set.iterator();
while(iterator.hasNext()){
System.out.println(iterator.next());
}
}
}
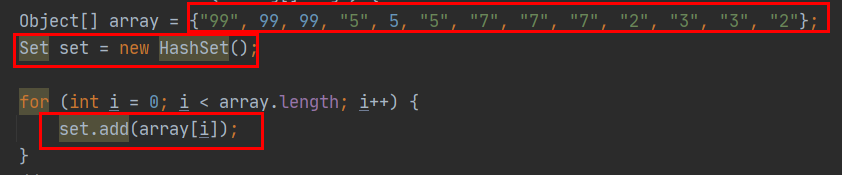
Object 배열을 HashSet에 입력하여 Set 인터페이스의 인스턴스로 사용한다.
add 는 컬렉션에 새로운 요소를 저장할 때 사용하는데 요소의 중복이 허용되지 않는다.
일부러 중복되는 데이터를 나열했다. 결과는 아래와 같다.
[99, 2, 99, 3, 5, 5, 7]Set에서 add 하는 과정에서 중복이 되는 요소들을 지워버린다. 그런데 99, 99 처럼 두개가 나온 요소가 있다. 이는 어떻게 된 것인가?
그 이유는 "99" 는 문자열이고 99 는 정수형이기 때문이다. 다시말해 "99"는 아스키코드 문자열로 취급하고 99는 정수형인 수로 취급되기 때문이다. set.add 하는 과정에서 "99" 와 99 는 다른 요소이므로 중복이 아니다. 같은 것은 99와 99이다. 언뜻 이해가 어려울 수 있지만 숫자와 문자는 엄연히 다르다.
또 한가지의 특징은 순서가 없다는 것이다. 위의 저장 순서에는 어떤 순서가 없다.
*HashSet 의 특징은
- 중복을 허용하지 않는다.
- 순서가 없다.
컬렉션마다 특성의 차이가 있으니 알고 있어야 한다.
HashSet의 인스턴스는 Iterator 로도 받을 수 있다.
* 중복을 제거하는 방법 HashSet
다음 예제코드는 중복을 제거하는 방법의 하나이다.
HashSet 클래스를 Set 으로 받고 LinkedList 에 Set 을 받아 List 로 사용하여 Collections 의 sort메서드를 사용한다.
자료의 변환과정이 상당히 길고 복잡해서 직관성이 떨어진다.
그런데 어쩔 수 없다. 자바의 엄격한 객체지향 프로그래밍의 규칙이 코드를 길게 만드는 것은 알려진 사실이다.
그만큼 안정성도 따른다는 것을 감안해야 한다. 단점이 있으면 장점도 있는 법이다.
package com;
import java.util.*;
public class Main {
public static void main(String[] args) {
Set set = new HashSet();
int num;
for (int i = 0; set.size() < 9; ++i) {
num = (int)(Math.random()*9+1);
set.add(num);
System.out.println("Try : " + set.size() + "| number : " + num
+ " | " + i + " times");
}
List list = new LinkedList(set);
Collections.sort(list);
System.out.println(list);
}
}이 예제는 랜덤으로 1부터 9까지 숫자를 뽑아서 중복되지 않는 10개의 숫자를 얻을 때까지 for문을 돌려본다.
총 20번의 시도로 9개를 뽑을 수 있었다. 랜덤 숫자의 범위를 9보다 적게하면 무한루프에 빠지고 더 넓게 하면 숫자간의 거리가 벌어지는 것을 볼 수 있다. for 루프의 조건이 set.size() < 횟수 이면 횟수보다 배열이 작으면 끝나지 않는다. 정수의 개수는 정해져 있으니까 중복을 제거하면 범위를 예상할 수 있다.
이 방법으로 로또번호를 추출하는 것도 가능하다.

* 객체(인스턴스)의 중복
HashSet 이 기본형 자료 (int 정수형 등)나 String 문자열에 대한 중복 검사가 가능하지만 클래스의 인스턴스를 걸러낼 수 있을까? 일단은 잘 안된다. 다음의 예제를 보자.
package com;
import java.util.*;
public class Main {
public static void main(String[] args) {
HashSet hashSet = new HashSet();
hashSet.add("Hello World!");
hashSet.add("Hello World!");
hashSet.add(999);
hashSet.add(999);
hashSet.add(999);
hashSet.add(new MyClass("JACK", 99));
hashSet.add(new MyClass("JACK", 99));
System.out.println(hashSet);
}
}
class MyClass{
String name;
int number;
public MyClass(String name, int number) {
this.name = name;
this.number = number;
}
@Override
public String toString() {
return "MyClass{" +
"name='" + name + '\'' +
", number=" + number +
'}';
}
}
문자열과 숫자만 요소에 추가할 시에는 필터링이 잘된다. 그런데 객체의 경우는 안된다. 똑같은 데이터를 가진 객체를 생성했음에도 불구하고 말이다.
객체의 참조에 대한 지식이 있다면 왜 그런지 예상이 가능할 것이다. 두개의 객체는 현재 히프 메모리 상에 독립적으로 존재하는 것이다.
두 인스턴스를 같은 것으로 인식하려면 별도의 방법이 필요하다.
그전에 HashSet은 중복을 어떻게 판단하는가? 기준을 알아둘 필요가 있다.
값이 중복인지 알기 위해 두개 메서드를 호출한다.
equals 와 hashCode 이다.
먼저 "Hello World!" 를 알아보자. 이것이 String 객체인것을 잘 의식하지 않고 사용하지만 객체이다. 문자열 리터럴은 메서드를 사용할 수 있다.
자바의 내부 구조를 이해하는 것은 시간이 걸리며 어려운 일이다. 그것은 자바 언어 개발자가 기술한 내부 문서를 들여보는 수고가 필요하다. 애플리케이션을 만드는 사람들이 처음부터 보기는 어려운 문서다.
대신에 바깥에서는 몇가지 메서드를 테스트한 결과값으로 이해하는게 좀 더 빠르다.
다음 예제를 보자. a, b, c 는 각기 다른 참조변수지만 equals 와 hashCode값은 모두 같다.
String a = "Hello";
String b = "Hello";
String c = "Hello";
System.out.println("Hello".hashCode());
System.out.println(a.hashCode());
System.out.println(b.hashCode());
System.out.println(c.hashCode());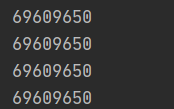
System.out.println(a.equals("Hello"));
System.out.println(a.equals(b));
System.out.println(b.equals(c));
System.out.println(c.equals(a));
해쉬코드는 자바에서 메모리와 클래스를 관리하는 고유의 주소체계라고 볼 수 있다. 엄밀히 말하면 메모리의 주소와는 다르게 작동하는데 초보자가 이해하려면 꽤 많은 시간이 걸리는 이야기다.
C언어는 직접적으로 메모리의 주소를 사용하지만 자바에서는 해쉬의 (key : value) 방식을 사용한다. 이것이 더 객체지향 스러운 시스템이기도 하다. 그냥 주소를 알려주는게 아니라 '추상화' 계층을 만들어서 사용한다. 어쨋든 직관적으로 이해하기는 힘드니 좀 더 쉬운말로 하자.
객체를 참조할 변수가 3개나 있는데 "Hello" 문자열을 가리키고 있다. 자바가 비교할 때는 해쉬코드를 읽어와서 equals 메서드로 비교한다. 끝이다.
문자열 뿐 아니라 숫자도 비교가능하다.
System.out.println(new Integer(5).hashCode());
System.out.println(new Integer(5).hashCode());
System.out.println(new Integer(99).hashCode());위의 실행결과는\
5
5
99
이다.
System.out.println(new Integer(5).equals(new Integer(5)));이 결과도 true 이다.
기본형은 이렇게 비교가 가능하지만 객체는 인스턴스를 생성하면 각각 다른 해쉬코드가 생성된다. 이런 경우 equals 와 hashCode 를 오버라이드 해주면 된다. 이것도 많이 쓰는 것이기 때문에 인텔리제이 같은 IDE 에는 코드 생성기능이 들어있다.

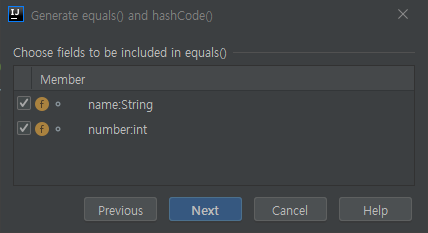
equals 와 hashCode 를 오버라이드 한다. (인텔리제이 코드 자동생성)
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
MyClass myClass = (MyClass) o;
return number == myClass.number &&
Objects.equals(name, myClass.name);
}
@Override
public int hashCode() {
return Objects.hash(name, number);
}

다시 실행하니 중복이 제거되었다.
* 집합 구하기 예제
package com;
import java.util.HashSet;
import java.util.Iterator;
public class Main {
public static void main(String[] args) {
// write your code here
HashSet setA = new HashSet();
HashSet setB = new HashSet();
HashSet setInter = new HashSet();
HashSet setUnion = new HashSet();
HashSet setDifference = new HashSet();
// 집합 A
for (int i = 1; i <= 7; i++) {
setA.add(i);
}
System.out.println("setA = " + setA);
// 집합 B
for (int i = 5; i <= 11; i++) {
setB.add(i);
}
System.out.println("setB = " + setB);
// 교집합
Iterator it = setB.iterator();
while(it.hasNext()){
Object temp = it.next();
if(setA.contains(temp))
setInter.add(temp);
}
//합집합
it = setA.iterator();
while(it.hasNext())
setUnion.add(it.next());
it = setB.iterator();
while(it.hasNext())
setUnion.add(it.next());
it = setA.iterator();
while(it.hasNext()){
Object temp = it.next();
if(!setB.contains(temp))
setDifference.add(temp);
}
System.out.println("setInter = " + setInter);
System.out.println("setUnion = " + setUnion);
System.out.println("setDifference = " + setDifference);
}
}
HashSet을 사용한 집합구하기 예제이다.
코드를 읽고 해석해본다. 중학수학에서 배웠던 내용을 자바의 알고리즘을 사용하면 충분히 재연가능하다.
Iterator 가 유용하게 쓰인다. while 루프를 돌때 HashSet의 add 메서드는 자체적으로 중복을 걸러낸다.
Iterator의 사용법은 간단하면서도 강력하니 잘 챙겨두도록 한다.
익숙해지면 점점 for 문보다 Iterator 를 쓰게된다.
